
Please note that this tutorial requires the user to have a basic understanding of the options available in Jupyter. If you are not familiar with Jupyter, we recommend exploring other tutorials in section to get started:
Introduction
The .ipynb file format stands for IPython Notebook, which was the original name of Jupyter Notebook. This file format allows users to create and share interactive documents that contain:
- live code,
- equations,
- visualizations, and
- narrative text (documentation, comments).
Notebooks can be used for a wide range of purposes, including data exploration, data visualization, machine learning, and scientific research.
Notebooks consist of a series of cells, which can be either code cells or markdown/text cells.
-
Code cells contain executable code in the programming language of your choice (e.g. Python, R, Julia, etc.). The code cells can be executed in the notebook, allowing you to see the output of your code and visualize your data in real time.
-
Markdown cells contain formatted text and equations written in Markdown or LaTeX. The markdown cells can be rendered in the notebook, providing the project description in the user-friendly way.
-
Output cells is typically displayed in a separate cell below the input cell. This separation allows for a cleaner and more organized presentation of the code and its results. The output cells can contain interactive plots, graphical components, and dynamic visualizations. These output cells can be hidden or shown at will by the user.
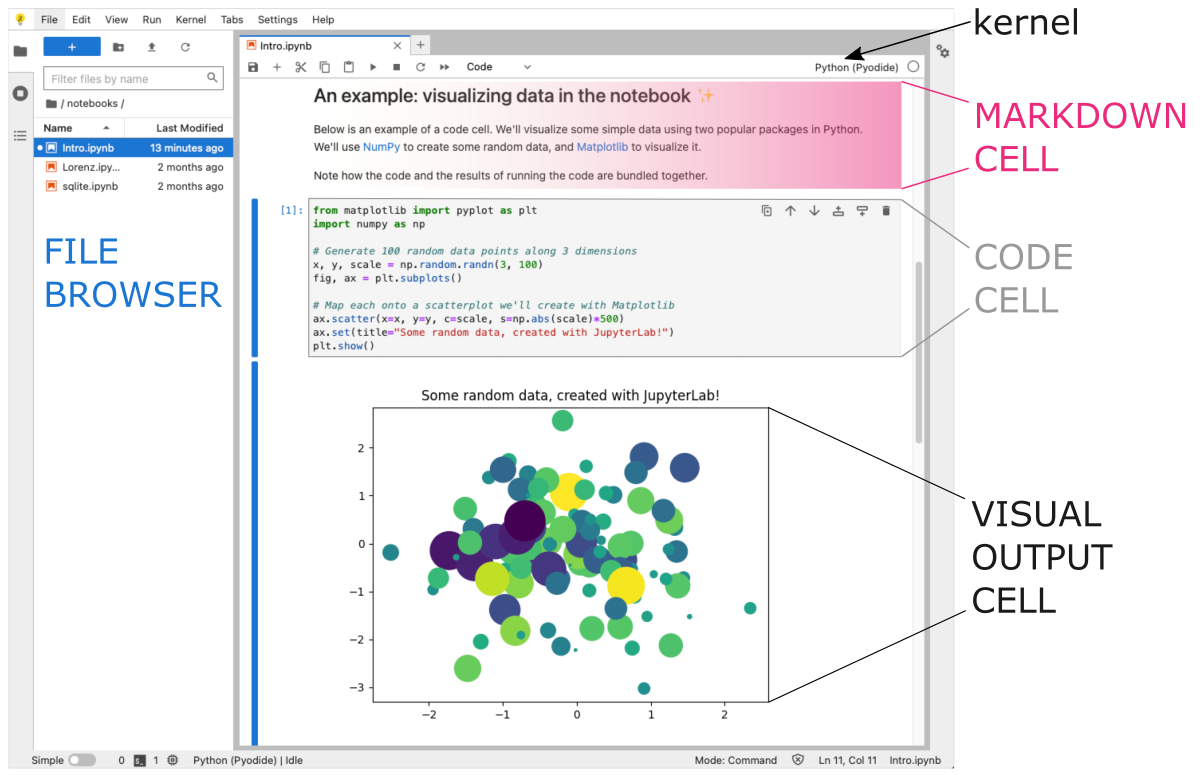
Notebooks can be easily shared as a .ipynb file or hosted on online platforms (e.g., Google Colab ⤴), allowing collaborators to access and modify the same document in real-time, which streamlines collaboration and helps to reduce errors and redundancies.
Online Notebook Platforms
There are several online options to create a .ipynb notebook:
-
Try-Jypyter platform https://jupyter.org/try ⤴
Jupyter Try is a web-based platform that allows users to try out Jupyter notebooks without having to install anything locally. It provides access to a virtual machine that comes pre-installed with the Jupyter Notebook environment and a selection of popular scientific libraries. -
Google Colab https://colab.research.google.com/ ⤴
Google Colab is a free Jupyter Notebook environment provided by Google that allows you to write and execute Python code in the cloud. It comes with pre-installed libraries and supports GPU acceleration for machine learning workloads. -
Microsoft Azure https://notebooks.azure.com/ ⤴
Microsoft Azure provides a cloud computing platform and a variety of services, including Azure Notebooks, which allows users to create and share Jupyter-like notebooks in the cloud. -
IBM Watson Studio https://www.ibm.com/cloud/watson-studio ⤴
IBM Watson Studio is a cloud-based data science platform that provides a suite of tools for building, training, and deploying machine learning models. It includes a Jupyter Notebook environment, as well as data preparation tools, model development tools, and deployment tools. -
Kaggle Kernels https://www.kaggle.com/kernels ⤴
Kaggle Kernels is a cloud-based environment for creating, running, and sharing data science projects. It supports Jupyter Notebook and RStudio, and provides access to a variety of datasets, pre-installed libraries, and GPU resources. -
Databricks https://community.cloud.databricks.com/login.html ⤴
Databricks is a cloud-based data analytics platform that provides a collaborative environment for data scientists, data engineers, and business analysts. It supports Jupyter Notebook, as well as SQL, streaming, and machine learning workloads.
Is Python in an online notebook always good?
Online notebooks can be a great tool for interactive data analysis and collaboration.
The notebook .ipynb is primarily designed for interactive computing, data exploration, and rapid prototyping, making it an excellent tool for tasks like data analysis, data visualization, and machine learning.
Online notebooks can be accessed from any computer with an internet connection, allowing you to work from anywhere.
Online notebooks make it easy to collaborate with others in real time, as multiple users can edit the same notebook simultaneously.
Many online notebook platforms come with pre-installed libraries, making it easy to get started with data analysis and machine learning.
Some online notebook platforms offer access to high-performance hardware resources like GPUs and TPUs, which can speed up machine learning workloads.
While online notebooks can be a convenient and accessible way to work with Python, there are some potential drawbacks to consider:
For small Python scripts or large modular Python developments a plain text file script .py or IDEs such as Visual Studio Code (VSC) or PyCharm are often a better choice than Jupyter, since they offer more advanced features, like debugging, refactoring, and testing, that are essential for professional development.
Online notebooks may not provide as much flexibility and customization as locally-installed versions of Jupyter. This can be a limitation if you need to install specific libraries or modify the environment in other ways.
Depending on the complexity of your code and the amount of data you’re working with, online notebooks may be slower to execute than a local installation of Python.
Working with sensitive data in an online notebook can pose security risks, as the data may be stored on a remote server that you don’t control. It’s important to carefully consider the security implications of using online notebooks, and to take appropriate precautions to protect your data.
Some online notebook platforms require a subscription or incur charges for access to additional resources, which may be an issue for those working on a tight budget.
try-jupyter online
The Jupyter Project offers an online training platform called “Try Jupyter” that allows users to get started with Python projects in Jupyter without having to install any software on their own computer.
The Try Jupyter ⤴ online coding platform provides Python kernel with the Pyodide ⤴ distribution.
Pyodide is a Python runtime environment that runs entirely in the browser using WebAssembly. It includes the Python interpreter, standard library (limited modules only), and a number of third-party libraries (e.g., numpy, pandas, scipy, scikit-learn, matplotlib, pillow, and more ⤴), all of which can be used directly in the browser without requiring any installation or setup. Pyodide was developed by Mozilla and is part of the larger WebAssembly project.
PROS & CONS
A good option to quickly see if working in JupyterLab is for you.
You don't even need to install Jupyter Lab, all you need is an Internet connection.
Most useful libraries are available without additional installation.
You don't need an account or to sign in. Just open the jupyter-try and start using it!
You can't install custom libraries.
You can't easily load files from your local file system (running a simple local HTTP server ⤴ is required)
You can't easily load data files and images from online resources.
Get started on a platform
Here’s how you can use the platform:
1. Open any web browser and go to the Try Jupyter website: https://jupyter.org/try ⤴
2. Click on the Try button in the top menu bar and then click on the Try JupyterLab section, to launch the Jupyter user interface in your browser.
Wait for the platform to load. This may take a few moments.
3. Once the platform has loaded, you should be redirected to the URL: https://jupyter.org/try-jupyter/lab/ ⤴. Now, you can start a new notebook:
- using the Launcher shortcuts by clicking on the
Python (Pyodide)button in the Notebook section
or
- using the top menu bar:
File : New : Notebookand selectingPython (Pyodide)from the drop-down menu.
The new notebook should appear as a new tab in your JupyterLab interface.
4. You can rename the notebook file by double clicking on the filename in the File browser panel on the left-hand side. My notebook is called scatterplot.ipynb.
You can now start writing Python code in the notebook cells and running them by clicking on the Run button in the top menu bar or pressing Shift + Enter to run the current cell and select the cell below it.
plot using matplotlib
5. Example Python-based notebook for creating scatterplot using matplotlib.
In this example, we create the set of 100 random 3-dimensional points using numpy library. Then we will use a matplotlib functions to plot the dataset as a 2-dimensional scatterplot with a third dimension determining the size of the points.
NumPy ⤴ is a Python library for numerical computing that includes a random ⤴ module for generating random numbers and arrays.
Both libraries are included within the Pyodide distribution, so no installations are required.
STEP A: Add a markdown cell in the notebook providing the introduction to your project
You can copy the text provided below and paste it into the first cell in the notebook.
In this project, we will explore the use of:
* `matplotlib`, a Python data visualization library, to create a scatterplot
* `random` module of the `numpy` library, to generate a dataset for plotting, composed of 100 3-dimensional points.
*Through this exercise, we aim to showcase the potential of these powerful tools in effectively representing and visualizing complex data sets. By leveraging the capabilities of Matplotlib and Numpy, we hope to provide insights into the relationships and patterns that can be inferred from the given dataset.*
Now, change the cell type from code to markdown in the top menu bar in the notebook section.
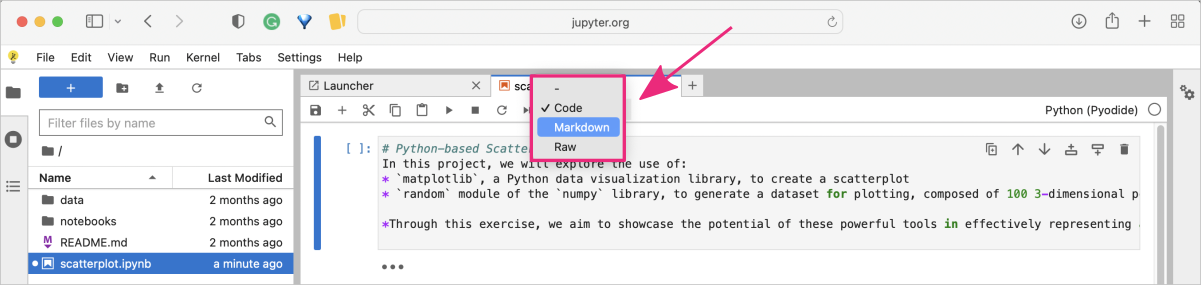
To learn more about Markdown syntax and benefits, check out the practical tutorial in Section 09. Project Management / Documentation Improvement Tool. It will provide you with a hands-on experience of using Markdown to format text, add images, create lists, and more.
Don’t miss out on this opportunity to enhance your skills!
To execute the cell press Alt + Enter ( use option + return for macOS ).
This will render the markdown content and add a new cell below. By default, new cells are always of the code type.
STEP B: Add a code cell to import required modules
In the next cell add Python code for all required imports, i.e., numpy and matplotlib.
# import modules
import numpy as np # to generate random dataset
from matplotlib import pyplot as plt # to create scatterplot
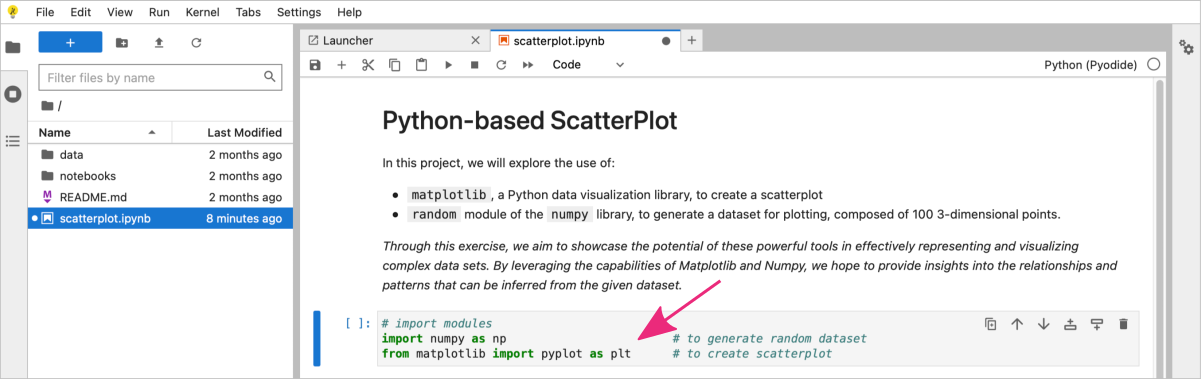
To execute the code cell, again press Alt + Enter ( use option + return for macOS ).
STEP C: Add a code cell to create the python code
In the next code cell add Python code for generating the dataset and creating the scatterplot.
#1 Generate 100 random data points along 3 dimensions
x, y, scale = np.random.randn(3, 100)
#2 Create a scatter plot
fig, ax = plt.subplots()
#3 Add dataset to the scatterplot
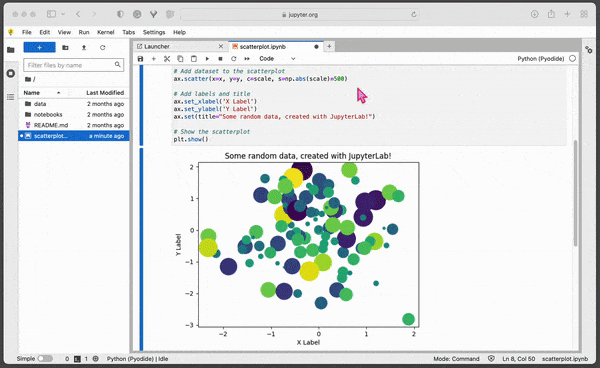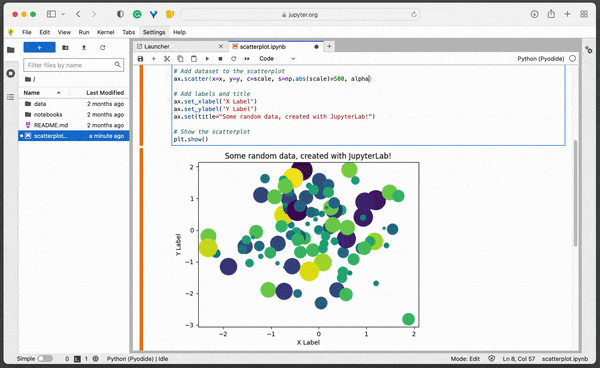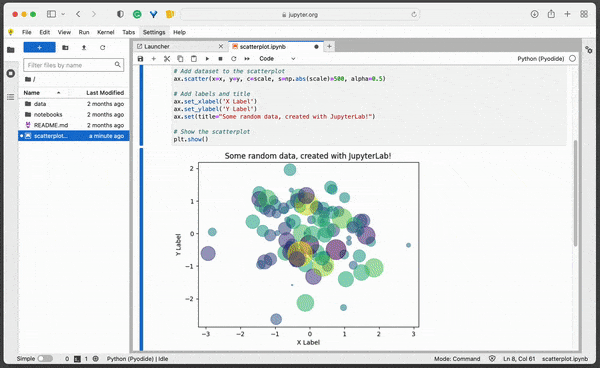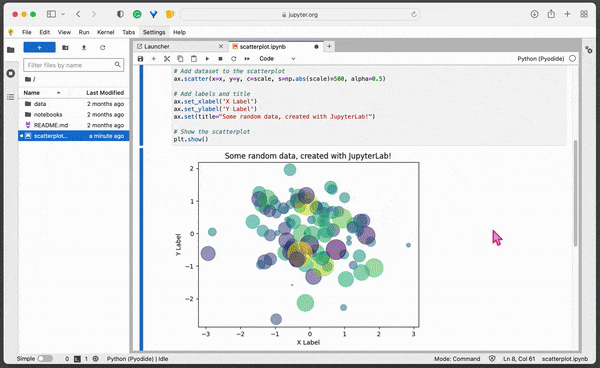
ax.scatter(x=x, y=y, c=scale, s=np.abs(scale)*500)
#4 Add labels and title
ax.set_xlabel('X Label')
ax.set_ylabel('Y Label')
ax.set(title="Some random data, created with JupyterLab!")
#5 Show the scatterplot
plt.show()
What the script does?
#1 Generate 100 random data points along 3 dimensions
The numpy libarary includes a random module. One of the functions provided by numpy.random is randn(). This function generates an array of random numbers drawn from a standard normal distribution. The arguments of the function determine the the shape of the generated array.
x, y, scale = np.random.randn(3, 100)
In this example we create a 2D array with 3 rows (x, y, scale) and 100 columns containing random numbers. We split the array by row dimension into three separate objects. By organizing the data this way, we can easily manipulate the point coordinates (x and y) and scale their size.
#2 Create a scatter plot
Matplotlib library creates a figure that can contain one or more subplots within it.
Subplots are essentially smaller plots within a larger plot, which can be useful for visualizing multiple sets of data or for creating more complex visualizations.</span>
The plt.subplots() function returns two values:
- a figure object (fig) and
- an array of axes objects (ax).
fig, ax = plt.subplots()
The figure object represents the entire plot, while the axes objects represent the individual subplots within the plot. When no arguments are provided, a single subplot is created by applying the default settings plt.subplots(nrows=1, ncols=1).
#3 Add dataset to the scatterplot
The ax.scatter() is a function in the Matplotlib library that is used to create a scatter plot. It takes in a set of x and y coordinates, along with some optional arguments, and plots them as individual points on a 2D plane. The basic syntax for ax.scatter() is as follows:
ax.scatter(x, y, s=None, c=None, marker=None, cmap=None, alpha=None)
where:
| param | description | notes |
|---|---|---|
x |
is a sequence of x coordinates for the points to be plotted | |
y |
is a sequence of y coordinates for the points to be plotted | |
c |
is the color of the markers | This can be a single color, or a sequence of colors that correspond to each point in the plot. |
s |
is the size of the markers (points) in the scatter plot | This can be a scalar value, or a sequence of values that correspond to each point in the plot. |
marker |
is the shape of the markers | This can be a string specifying a built-in marker shape (e.g., ‘o’ for circles), or a custom marker object. |
cmap |
is a colormap object that maps the c values to a range of colors |
|
alpha |
is the transparency of the markers |
In this example, we use arrays of random values to set XY coordinates of the points and determine numerical range mapped to the default colorscale. The size of the points is the scale array transformed to absolute values using np.abs() function and multiplied by 500 to provide intiger sizes in range from 1 to 500.
#4 Add labels and title
In Matplotlib, the ax object is a reference to the axis of a plot. It provides various functions that can be used to customize the scatterplot and other types of plots.ax.scatter() function, some of the common functions that can be used to customize the plot include:
ax.set_xlabel()sets the x-axis label for the scatterplotax.set_ylabel()sets the y-axis label for the scatterplotax.set_title()sets the title of the scatterplotax.set_xlim()sets the limits of the x-axis for the scatterplotax.set_ylim()sets the limits of the y-axis for the scatterplot.
#5 Show the scatterplot
In Matplotlib, plt.show() is a function that displays all currently active figures. When you call plt.show(), Matplotlib will display any previously created plots that have not yet been shown.
The plt.show() function should typically be called at the end of the code block that creates a plot. This is because, until the plt.show() function is called, Matplotlib will hold the plot in memory, but won’t display it. This allows you to create multiple plots in a single script or code block and display them all at once.
To execute the code cell, again press Alt + Enter ( use option + return for macOS ).
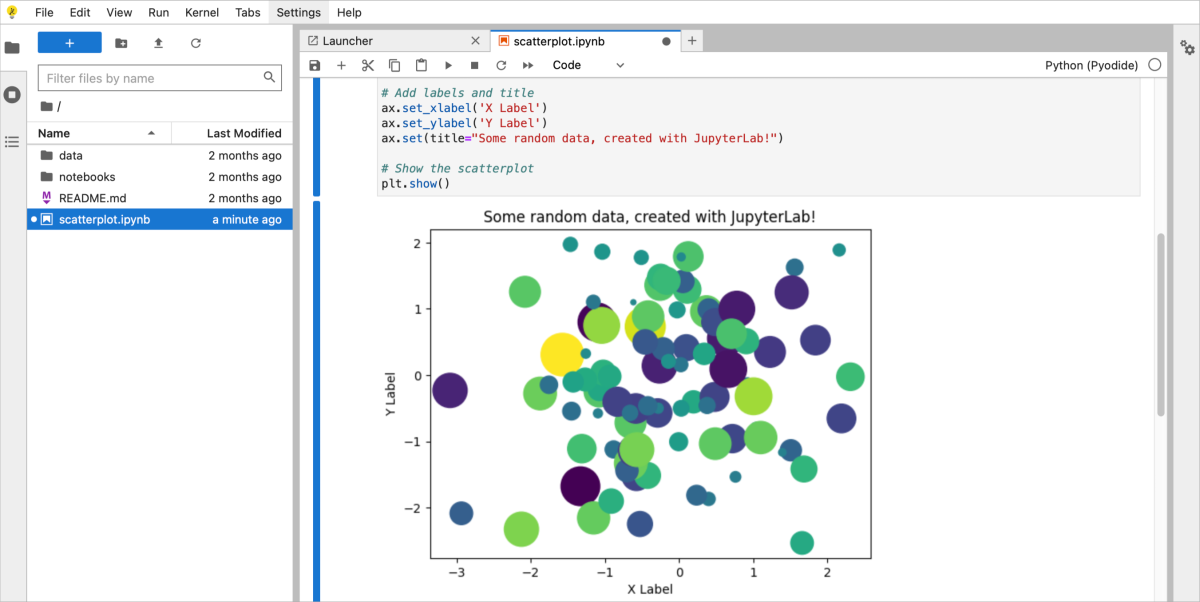
When you execute a code cell, the output generated by that cell is displayed below the code. If you want to modify the code, you can simply click on the cell and make changes to the code.
Once you’ve made the desired changes, you can execute the cell again by clicking on the Run button, or by using the keyboard shortcut Shift + Enter or Alt + Enter.
By editing and re-running cells, you can quickly test different variations of your code and see how they affect the output. This can be particularly useful if you want to explore different parameters or settings for your code.
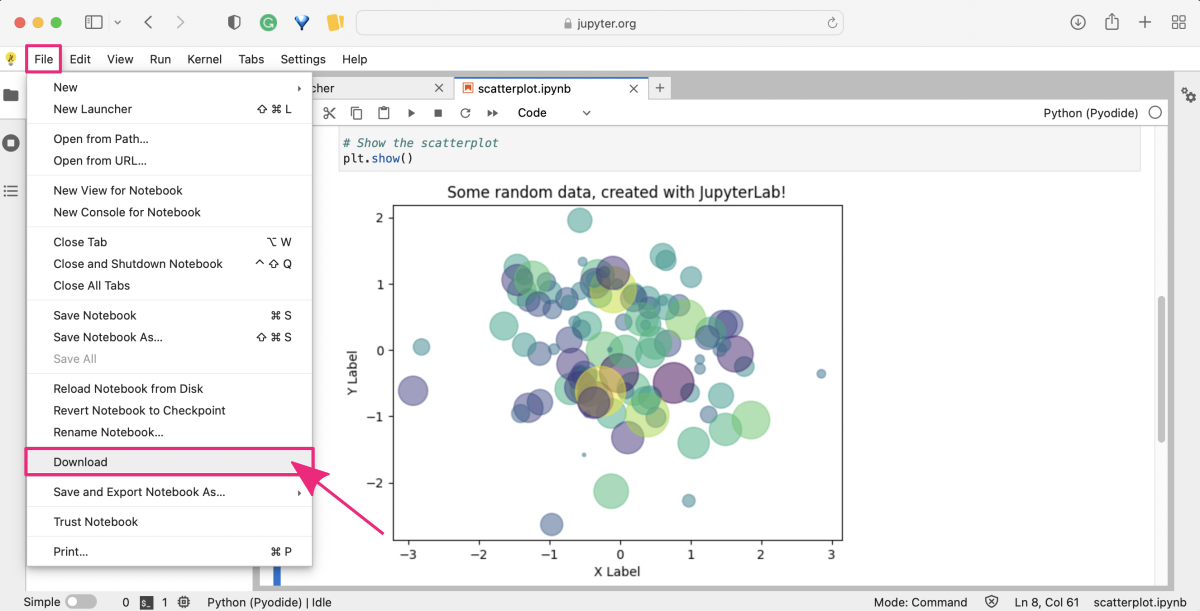
After completing your work in the try-jupyter notebook, you may wish to download it for either personal reference or to share with others. To do this, simply select File from the top menu, and then choose Download to obtain a local copy of the notebook.
Google Colab online
Google Colab ⤴ (short for research colaboratory) is a cloud-based service provided by Google that allows users to create, run, and share interactive Jupyter notebooks without the need to install any software on their computer.
Google Colab uses Python 3 as its default programming language. Specifically, it uses the Anaconda distribution of Python, which includes many popular Python libraries for scientific computing and data analysis. Colab notebooks can also leverage Google’s machine learning and data analysis services, such as TensorFlow ⤴ and BigQuery ⤴.
The use of the Anaconda ⤴ distribution of Python in Google Colab provides a convenient and flexible environment for data analysis and scientific computing, while also allowing users to install and use custom packages as needed.
PROS & CONS
You can create Jupyter notebooks in a web browser without any installation on your computer.
You can use the Google's high-powered cloud-based computing resources. (limited per user)
A variety of commonly used Python libraries are pre-installed. You can also install custom packages.
It is easy to collaborate simultaneously with others on the same notebook shared via a link.
Colab integrates with other Google services, such as Google Drive to easily store your projects.
You need a Google account to sign in and use Google Colab. (Google account ⤴ is free)
Colab sessions may time out after a certain period of inactivity.
There may be concerns about data security and privacy when working with sensitive data.
Get started on a platform
Here’s how you can use the platform:
1. Open any web browser and go to the Colaboratory website: https://colab.research.google.com ⤴
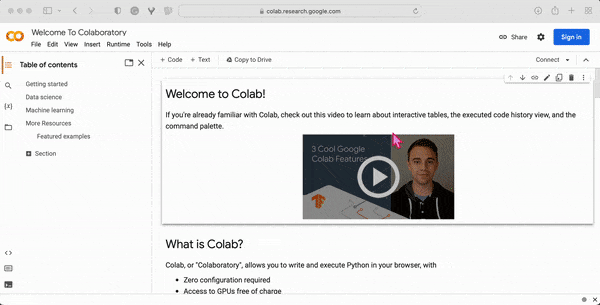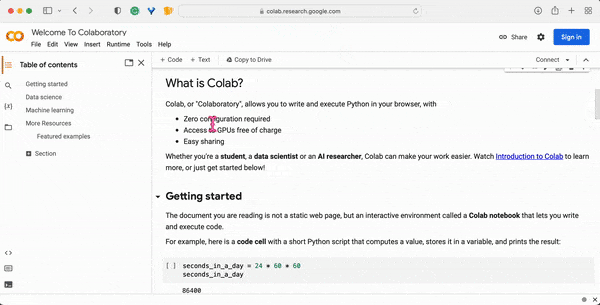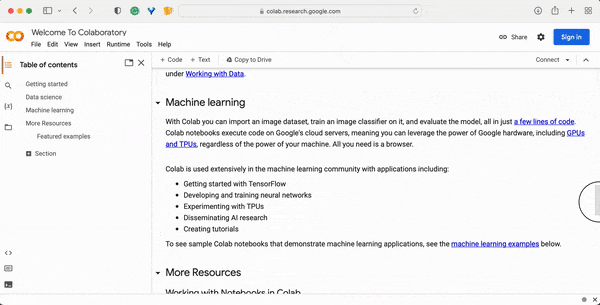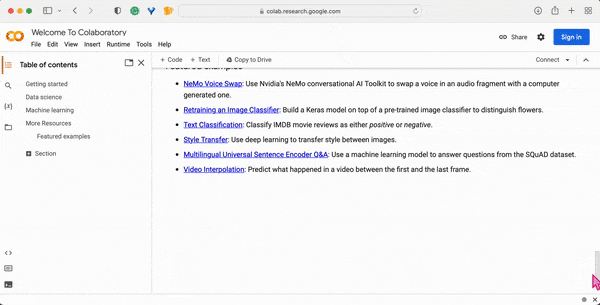
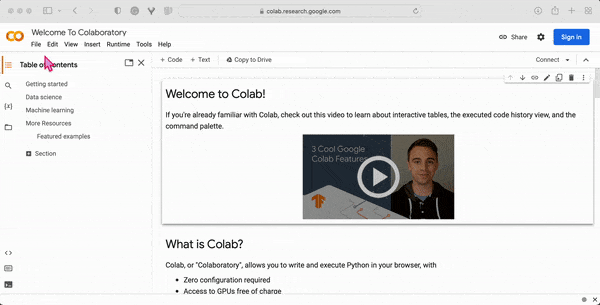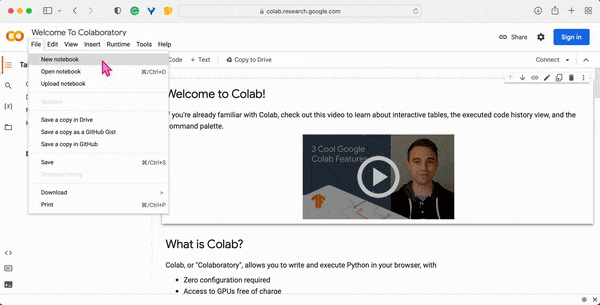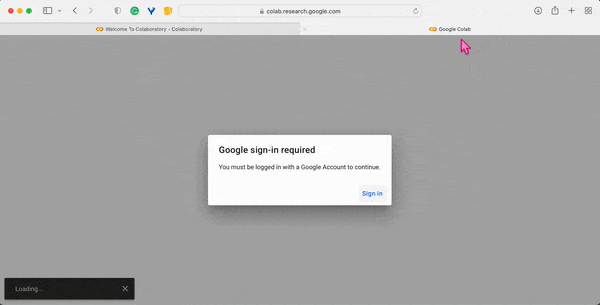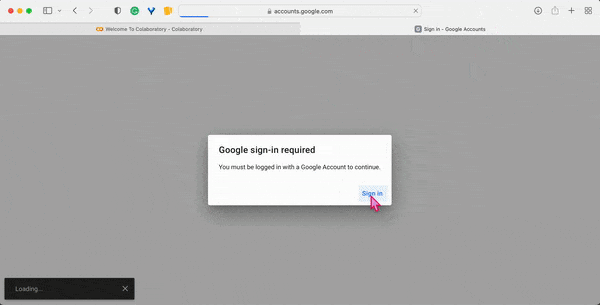
When you open the Google Colab website, you will land on the “Welcome to Colab” page, which provides a quick guide to “What is Colab?” The guide also provides a sample code snippet to help users get started with running their first Colab notebook. Further, you can find there some information about applications in data science and machine learning studies. Finally, you will get many useful links to in-depth resources for learning more about Colab and how to use it effectively.
2. Click on the File button in the top menu bar and then click on the New Notebook option, to launch the Colab-Jupyter user interface in your browser. Sign in to get access to your Google account.
Once successfully logged in, the new notebook will appear in your browser tab, and you should be redirected to the URL: https://colab.research.google.com/drive/ ⤴ followed by the random string encoding the address of your new notebook.
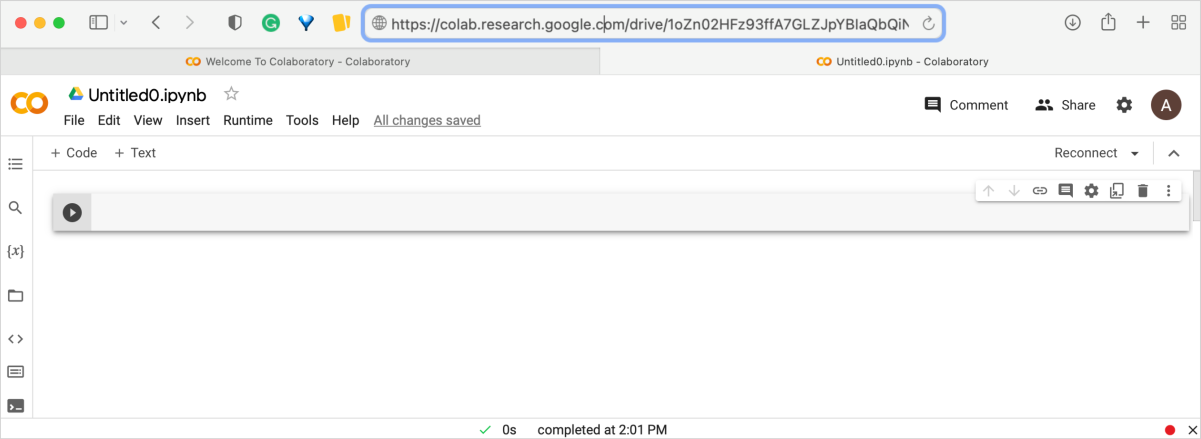
While Jupyter and Colab share many similarities, there are a few key differences in their user interfaces and workflows. Colab provides a more convenient way to run cells. Instead of having to use keyboard shortcuts or click a toolbar button, you can simply click the button on the left end of the cell. This button looks like a triangle or a play button, and it lets you run the cell with a single click. It is convenient if you’re using Colab on a touch-enabled device.
Colab provides many other features. Here’s the quick look on the options available in the Colab interface.
This option allows you to change the name of your notebook. By default, your notebook will be named “Untitled.ipynb”, but you can rename it to something more descriptive by clicking on the current name and typing in a new name.
This option allows you to search for specific text in your notebook and replace it with something else. You can use this option to quickly make changes to your code, for example, if you need to replace a variable name throughout your notebook.
This option allows you to view all the variables that are currently defined in your notebook, along with their values and data types. This can be helpful for debugging your code and understanding how different parts of your notebook are connected.
This option provides a file browser for navigating and managing the files in your Google Drive. You can use this option to create new folders, upload and download files, and open notebooks and other files in Google Colab.
This option provides a collection of pre-written code snippets that you can use as a starting point for your own code. The code snippets are organized by topic, such as “Data Loading”, “Model Training”, and “Visualization”.
This option allows you to quickly access various commands and features in Google Colab using a search interface. You can use this option to quickly find shortcuts without having to navigate through menus and options.
This option provides a terminal interface that allows you to run commands directly on the underlying operating system of your Google Colab instance. This can be useful for running system commands, installing software, and managing files outside of your notebook. (available only in the ColabPro)
3. You can rename the notebook file by clicking on the filename which activates the edit mode. My notebook is called scatterplot_seaborn.ipynb.
You can now start writing Python code in the notebook cells. Run your code by clicking on the Run button next to the cell or pressing Ctrl + Enter (while having cursor within a cell).
scatterplot using seaborn
4. Example Python-based notebook for creating scatterplot using seaborn.
In this example, we use a ready-made Wine dataset loaded from the sklearn library. Then we will use a seaborn functions to plot some dataset characteristics as a 2-dimensional scatterplot with a third parameter determining the color of points.
Scikit-learn ⤴ is a a Python machine learning library that provides tools for data mining, data analysis, and machine learning tasks. It includes example datasets, for example Wine dataset ⤴ that contains the results of a chemical analysis of wines grown in the same region in Italy by three different cultivators. The dataset has 178 samples and 13 features.
All libraries are included within the Google Colab development environment,
so no installations are required.
When running code in Colab, you may encounter an error message that indicates that a library is not available: “ModuleNotFoundError: No module named XXX”.
To install a library that is not available in Colab, you can use the !pip install command:
!pip install library_name
This will install the library in your Colab environment, and then you should import it in your code:
import library_name
STEP A: Add a markdown cell in the notebook providing the introduction to your project
Hover the mouse over the top edge of the code cell to display buttons for adding an additional text cell above.

You can copy the text provided below and paste it into the new text cell in the notebook.
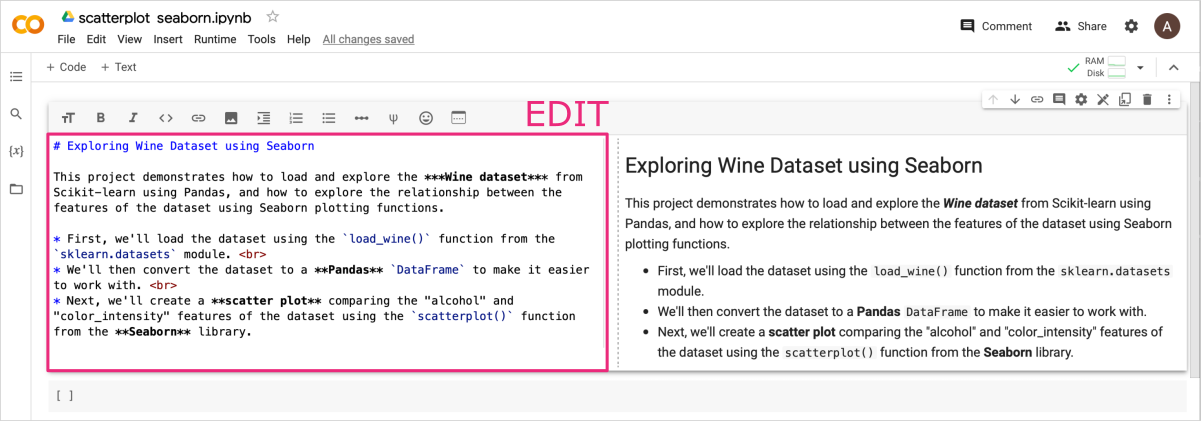
This project demonstrates how to load and explore the ***Wine dataset*** from Scikit-learn using Pandas, and how to explore the relationship between the features of the dataset using Seaborn plotting functions.
* First, we'll load the dataset using the `load_wine()` function from the `sklearn.datasets` module.
* We'll then convert the dataset to a **Pandas** `DataFrame` to make it easier to work with.
* Next, we'll create a **scatter plot** comparing the "alcohol" and "color_intensity" features of the dataset using the `scatterplot()` function from the **Seaborn** library.
After pasting the text, you will see the editing interface on the left and a preview of the rendered markdown on the right. You can customize the formatting to your liking.
To learn more about Markdown syntax and benefits, check out the practical tutorial in section 09. Project Management / Documentation improvement tools. It will provide you with a hands-on experience of using Markdown to format text, add images, create lists, and more.
Don’t miss out on this opportunity to enhance your skills!
To render the text cell press Shift + Enter.
This will render the markdown content and move your cursor to the cell below.
STEP B: Add a code cell to import required modules
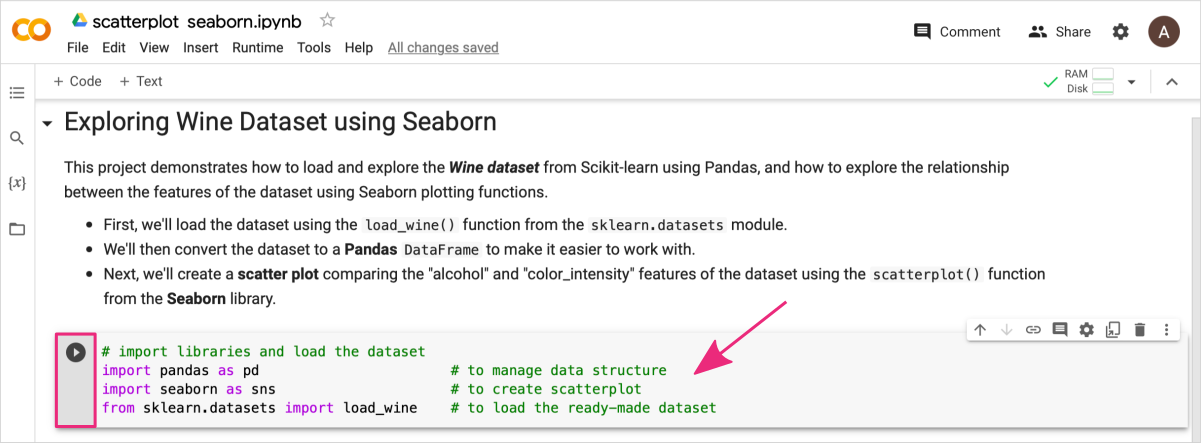
In the next code cell add Python code for all required imports, i.e., pandas, seaborn, and wine dataset from the sklearn.
# import libraries and load the dataset
import pandas as pd # to manage data structure
import seaborn as sns # to create scatterplot
from sklearn.datasets import load_wine # to load the ready-made dataset
To execute the code cell, press Shift + Enter or click the Run button.
STEP C: Add a code cell to create the python code for loading the dataset
Add next code cell, and copy-paste Python code for loading the dataset and exploring its contents.
#1 Load the Wine dataset
wine_data = load_wine()
#2 Preview dataset structured
# print(wine_data.DESCR) # optional: uncomment this line to see the dataset description
print(f'KEYS: {list(wine_data.keys())}\n') # optional
print(f'TARGETS: {wine_data.target_names}\n') # optional
print(f'FEATURES: {wine_data.feature_names}\n') # optional
#3 Convert the dataset to a Pandas DataFrame
df = pd.DataFrame(wine_data.data, columns=wine_data.feature_names)
df['target'] = wine_data.target
print(f'DATAFRAME:\n{df.head()}') # optional
What the script does?
#1 Load the Wine dataset
First, we call load_wine() function imported from the sklearn.datasets module.
wine_data = load_wine()
This loads the wine dataset as a Python object of a dictionary type.
#2 Preview dataset structured
Then, using a print() function, we can preview, what is the structure of the dataset and how to extract the information we need. The dictionary object in Python has a built-in method dict.keys() that returns the list of the keys available in the dictionary.
print(f'KEYS: {list(wine_data.keys())}\n')
In this case, we receive the following keys:
['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names']
The value corresponding to each key can be previewed as an attribute of the dictionary object, i.e., dict.attribute:
wine_data.DESCR # returns decription of the dataset
wine_data.feature_names # returns names of the measured features
#3 Convert the dataset to a Pandas DataFrame
Once you know what is in the dataset, you can create a well-structured Pandas DataFrame object containing the information you need. In this case, we build the DataFrame using information from the data field with column headers from the feature_names field.
df = pd.DataFrame(wine_data.data, columns=wine_data.feature_names)
We also want to know to which target class the observations belong so we add an additional column to the DataFrame we created in a previous step:
df['target'] = wine_data.target
Now, we can use a structured form of the dataset to create plots.
To execute the code cell, press Shift + Enter or click the Run button.
Note that in Colab, the result of procedures performed in a cell with a code is displayed just below but within the same cell. In the Jupyter interface, the output appears as a separate next cell.
Just below the code snippet in your notebook, you should see the output of the print() function:

This part of the output shows the structure of the wine dataset loaded from the sklearn library. It is a dictionary with 6 key:value elements. The wines are classified to 3 target categories. For all wines were collected 13 different measurements, i.e., features.

This part of the output shows the structure of dataset transformed to the DataFrame object. The first 5 samples of the Wine dataset is displayed, which include the names of the features and their corresponding values.
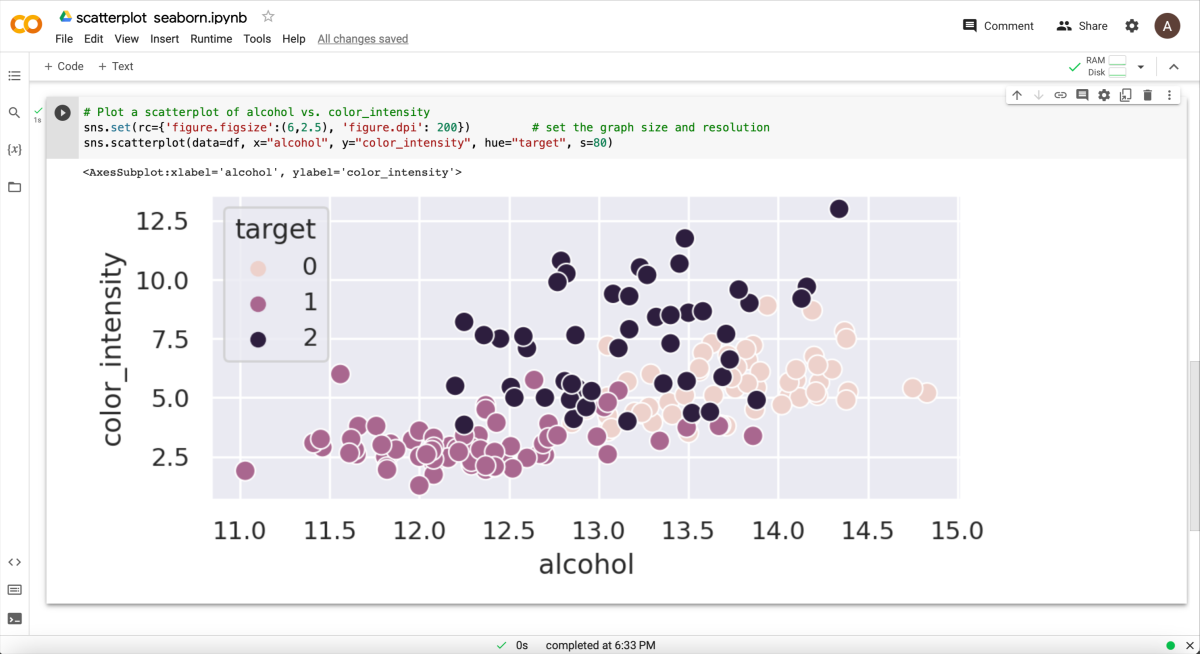
STEP D: Add a code cell to create the scatterplot using seaborn
Add next code cell, and copy-paste Python code to create a scatter plot comparing the “alcohol” and “color_intensity” features of the dataset.
# Plot a scatterplot of alcohol vs. color_intensity
sns.set(rc={'figure.figsize':(6,3), 'figure.dpi': 200}) # set the graph size and resolution
sns.scatterplot(data=df, x="alcohol", y="color_intensity", hue="target", size=80)
What the script does?
#1 Configure a graph settings
Seaborn’s sns.set() function is used to customize the appearance of plots created using Seaborn. It can be used to change the default settings for font size, color palettes, plot styles, and more. The rc parameter in Seaborn’s sns.set() function allows you to specify values for Matplotlib’s runtime configuration parameters. These parameters control a wide variety of aspects of the plot, including the figure size ('figure.figsize'), resolution ('figure.dpi'), font size ('font.size'), axes ('axes.labelsize', 'axes.titlesize'), line styles ('lines.linewidth', 'lines.linestyle'), and more.
sns.set(rc={'figure.figsize':(6,3), 'figure.dpi': 200})
Here are some of the available options for sns.set():
| param | description | options |
|---|---|---|
palette='deep' |
sets the color palette for the plot | 'deep', 'muted', 'pastel', 'bright', 'dark', 'colorblind' |
style='darkgrid' |
sets the overall style of the plot | 'ticks', 'darkgrid', 'whitegrid', 'dark', 'white' |
font='arial' |
a dictionary specifying the font properties | |
context='poster' |
a string specifying the context in which the plot will be displayed | 'paper', 'notebook', 'talk', 'poster' |
#2 Plot using seaborn graphs
Seaborn provides a wide range of plot types for visualizing statistical data, including:
scatterplot, lineplot, histplot, kdeplot, rugplot, jointplot, pairplot, heatmap, clustermap, boxplot, violinplot, barplot, countplot, relplot.
These plot types are similar to those available in Matplotlib, but Seaborn provides several additional types of plots and additional functionality for customizing the visual style of the plots.
sns.scatterplot(data=df, x="alcohol", y="color_intensity", hue="target", size=80)
The scatterplot() function in Seaborn is used to draw a scatter plot of two variables with possible semantic grouping. Here are some of the options available for customizing the scatter plot in Seaborn:
| param | description |
|---|---|
| x, y | variables to be plotted on the x and y axes |
| data | DataFrame or array containing the data to be plotted |
| hue | variable used to group the data by color; this can be a categorical or numeric variable |
| markers | set of marker styles to use for the style variable |
| size | variable used to set the size of the markers; this can be a numeric variable or a categorical variable with a specified mapping of size values |
| sizes | minimum and maximum sizes to use for the markers |
| style | variable used to set the marker style; this can be a categorical variable with mapping of marker styles |
| palette | color palette to use for coloring the markers based on the hue variable |
| alpha | transparency of the markers |
| edgecolor | color of the marker edges |
| linewidth | width of the marker edges |
| ax | the matplotlib Axes object on which the plot should be drawn |
To execute the code cell, press Shift + Enter or click the Run button.
Further Reading
Local Python setup on your computing machine (installation needed)Shell & IDLE: Python code in a terminal or simple IDE (beginner)
Text editors: create Python code in terminal text files (intermediate)
Jupyter Lab: create an interactive Python notebook (advanced)
PyCharm: IDE for professional Python developers (professional)
R programming environment(s)
RStudio: integrated environment for R programming
Setting up RStudio
MODULE 05: Introduction to Programming