
Introduction
Web scraping is a more advanced task that requires a higher level of technical knowledge and programming skills than simple file transfers or API requests. In particular, web scraping is typically done using programming languages like Python, so it is recommended that users have a basic understanding of Python before attempting to scrape websites.
Web scraping is a technique used to extract data from websites by analyzing the website’s HTML code and identifying specific elements that contain the desired information.
Pros and Cons
The challenges of web scraping are primarily related to the fact that websites are designed for human consumption, and so the structure and format of the data on a website can be complex and inconsistent. As a result, web scraping often requires the use of advanced techniques like regular expressions and parsing algorithms to extract the desired data from a website.
It is important to carefully consider the pros and cons of web scraping before attempting to use it as a method for downloading data from online resources.
| PROS | CONS |
|---|---|
| automation Helps you extract data from multiple websites in an automated and efficient manner, saving you time and effort. |
efficiency It can be a time-consuming and resource-intensive process, especially for large websites with complex structures. |
| time-saving Scraping allows you to quickly gather data from websites in real-time and keep it updated regularly. |
data quality The quality of data obtained through web scraping can vary depending on the complexity of the website and the quality of the scraping code. |
| competitive advantage It allows you to gather information on your competitors’ products and services. |
ethical concerns Web scraping can potentially violate website terms of service or even copyright laws. |
| large-scale data collection You can collect large amounts of data from multiple sources, enabling you to gain valuable insights and make informed decisions. |
data availability Not all websites allow access to their data through scraping. Some may require special permissions or may block scraping attempts altogether. |
It is important to ensure that you have the legal right to scrape a website before attempting to do so.
Other methods like API requests or file transfers may be much faster and more efficient, providing higher-quality data with less effort.
Before attempting to scrape a website for data, it is often a good idea to explore other options for downloading the data first. In many cases, there may be simpler and more efficient methods available:
In some cases, reaching out to the developers of a resource directly may be the easiest and fastest way to obtain the data you need. Many online resources provide APIs or other tools for accessing their data, and their developers may be willing to help you find the best method for accessing the data you need.
What you need to get started?
To get started with web scraping, you will need a few key tools and skills. These include:
-
Basic knowledge of HTML, CSS, and JavaScript
Web scraping involves understanding how web pages are constructed and how to extract information from them. Basic knowledge of HTML, CSS, and JavaScript can be helpful in this regard. -
Familiarity with Python
Python is one of the most popular programming languages for web scraping, so having a basic understanding of Python is essential. -
Web scraping libraries
There are several popular Python libraries that are used for web scraping, including BeautifulSoup, Scrapy, and Selenium. These libraries provide tools and functions for extracting data from web pages. -
Persistence and attention to detail
Web scraping can be a time-consuming and challenging task that requires a high degree of persistence and attention to detail. The process often involves trial and error, as well as debugging and testing to ensure that the scraping code is working correctly.
Overall, web scraping is a powerful tool for extracting data from websites, but it requires a higher level of technical knowledge and programming skills than some of the other methods for downloading data from online resources.
Hands-on tutorial
In this example we will use Beautiful Soup library in Python to scrape data from a webpage and save it to a local file applying the following steps:
- Send a request to the webpage using a library like
requestsorurllib. - Parse the HTML content of the webpage using Beautiful Soup.
- Identify the specific elements containing the data you want to extract using Beautiful Soup’s tag, attribute, and text filters.
- Extract the data and save it to a local file using Python’s built-in input-output functions.
Install requirements
Below you can find some of the essential libraries and components you need for web scraping in Python. There are many other libraries and tools that you might find useful depending on the specific requirements of your project.
If you’re using a Python virtual environment, make sure to activate it before installing any packages to ensure that the packages are installed in the virtual environment and not globally.
If you do NOT like developing scripts in the command line text editors and are not familiar with any IDE, using a web-based development environment such as Jupyter Lab can be a great alternative as it provides a user-friendly interface that allows for interactive development, documentation, and visualizations.
To install and launch Jupyter Lab, follow steps provided in the practical tutorials in section
04. Development Environment / Jupyter: interactive web-based multi-kernel DE :
- Getting started with JupyterLab on a local machine
- Getting started with Jupyter Notebook on HPC systems
Once Jupyter Lab is installed, you can launch it directly from the command line by typing the following command:
jupyter lab
Python
Python is a popular high-level programming language that is good for web scraping due to its simplicity, readability, availability of powerful libraries and tools, and ability to handle a variety of data formats.
Python Installation:
- Go to the Python official website at https://www.python.org/downloads/ ⤴
- Download the latest version of Python for your operating system and architecture.
- Run the installer and follow the installation wizard.
If you run into trouble, go to the practical tutorials of this workbook in section 03. Setting Up Computing Machine: Various methods of software installation which will show you step-by-step how to install Python on a given operating system.
urllib
The urllib is a Python library that provides a simple and powerful interface for working with URLs, allowing you to make HTTP requests and handle the response data, making it a useful tool for web scraping.
urllib is included in the standard library of Python, which means it’s available in the Python distribution and doesn’t need to be installed separately. It simply requires to be included at the top of your Python script:
import urllib
It provides several modules for working with URLs, including urllib.request, urllib.parse, and urllib.error.
requests
This library is used to send HTTP requests and handle responses in Python. It provides a user-friendly interface for making requests and handling the response data. requests is not included in the standard library and needs to be installed separately.
Requests Installation:
- Open a terminal or command prompt.
- Type the following command to install requests:
pip install requests
BeautifulSoup
This library is used to extract data from HTML and XML documents. It provides a simple and intuitive interface to parse HTML and XML and extract the data you need. BeautifulSoup is not included in the standard library and needs to be installed separately.
BeautifulSoup Installation:
- Open a terminal or command prompt.
- Type the following command to install BeautifulSoup:
pip install beautifulsoup4
selenium
This library is used to automate web browsers and simulate user interactions with web pages. It can be used to scrape dynamic websites that require user interactions to load data. Many modern websites are dynamic, with content being loaded and rendered in real-time, making web scraping a more challenging task. selenium is not included in the standard library and needs to be installed separately.
selenium Installation:
- Open a terminal or command prompt.
- Type the following command to install selenium:
pip install selenium
In order to use Selenium for web scraping, the user will also need to download and install a Webdriver, which will act as a virtual user, interacting with the website and triggering the rendering of the specific parts of the page that the user wants to scrape.
Webdriver Installation:
- Open a terminal or command prompt.
- Type the following command to install webdriver:
pip install webdriver_manager
pandas
This library is used for data manipulation and analysis. It provides a powerful data structure for handling tabular data and various functions for data cleaning and preprocessing. pandas is not included in the standard library and needs to be installed separately.
pandas Installation:
- Open a terminal or command prompt.
- Type the following command to install pandas:
pip install pandas
That’s it! Once you’ve installed these libraries, you’re ready to start web scraping in Python.
Create web scraping script
Web scraping has become an increasingly important tool for researchers and data scientists looking to extract valuable information from online resources. In this practical tutorial, we will explore the process of web scraping by using a real-life example.
Simple Template Code
Here is a basic template of the Python web scraping script that demonstrates how to retrive data from a webpage using Beautiful Soup and save it to a local file:
import requests
from bs4 import BeautifulSoup
# send a request to the webpage
url = "https://example.com/data"
page = requests.get(url)
# parse the HTML content of the webpage
soup = BeautifulSoup(page.content, 'html.parser')
# identify the specific elements containing the data
data_elements = soup.find_all('div', class='data')
# extract the data and save it to a local file
with open('data.txt', 'w') as file:
for data_element in data_elements:
file.write(data_element.text + '\n')
This code sends a GET request to the webpage at https://example.com/data, parses the HTML content using Beautiful Soup, finds all div elements with the HTML class data, extracts the text content of each element, and saves it to a local file called data.txt. Of course, the specific details of web scraping will depend on the website you’re scraping and the data you’re trying to extract. You can see the real life example below in the next section.
Hard target: dynamic website
Web scraping is a powerful technique that allows you to extract data from websites and web services automatically, saving you time and effort in manual data collection. Many modern websites are dynamic, with content being loaded and rendered in real-time, making web scraping a more challenging task.
How to know the site is dynamic?
Background of the story:
In this practical tutorial, we will use web scraping to extract names and URLs of third-party software employed by a BIAPSS ⤴ web service during the bioinformatics analysis of protein sequences that undergo liquid-liquid phase separation (LLPS). This information is particularly useful for those who want to follow the backend pipeline of the web service and download and install all the tools required. Manually deriving this information from the web service documentation can be time-consuming and tedious, but with web scraping, we can quickly and easily retrieve the data and present it in a well-structured table that includes the tool name, URL and citation record.
Web scrap the BIAPSS web service (dynamic)
This tutorial will guide you through scraping the dynamic website and data parsing using Python, selenium, and webdriver for a Chrome browser. This exercise will equip you with the necessary skills to extract and manipulate data from dynamic websites and web services.
STEP 1. Find the fragment of the web resource from which you want to retrieve the data
Before starting the web scraping process, the first step is to navigate to the web service in a browser and locate the representative subpage that contains the data that you want to extract. This subpage could be a documentation page, a results page or any other page that includes the data you need.
In this case, we first open the BIAPSS web service and navigate to the Docs tab available at https://biapss.chem.iastate.edu/documentation.html ⤴. From the menu panel on the left-hand side select Tools & References section. Its content appears in the right-hand panel on the page.
The backend bioinformatics analysis of the web service employed over 20 third-party tools to provide a high-level insights of the phase separation process. Each tool has a short description with a URL to the source page linked to the software name. We can also easily obtain software-related publications in one go.
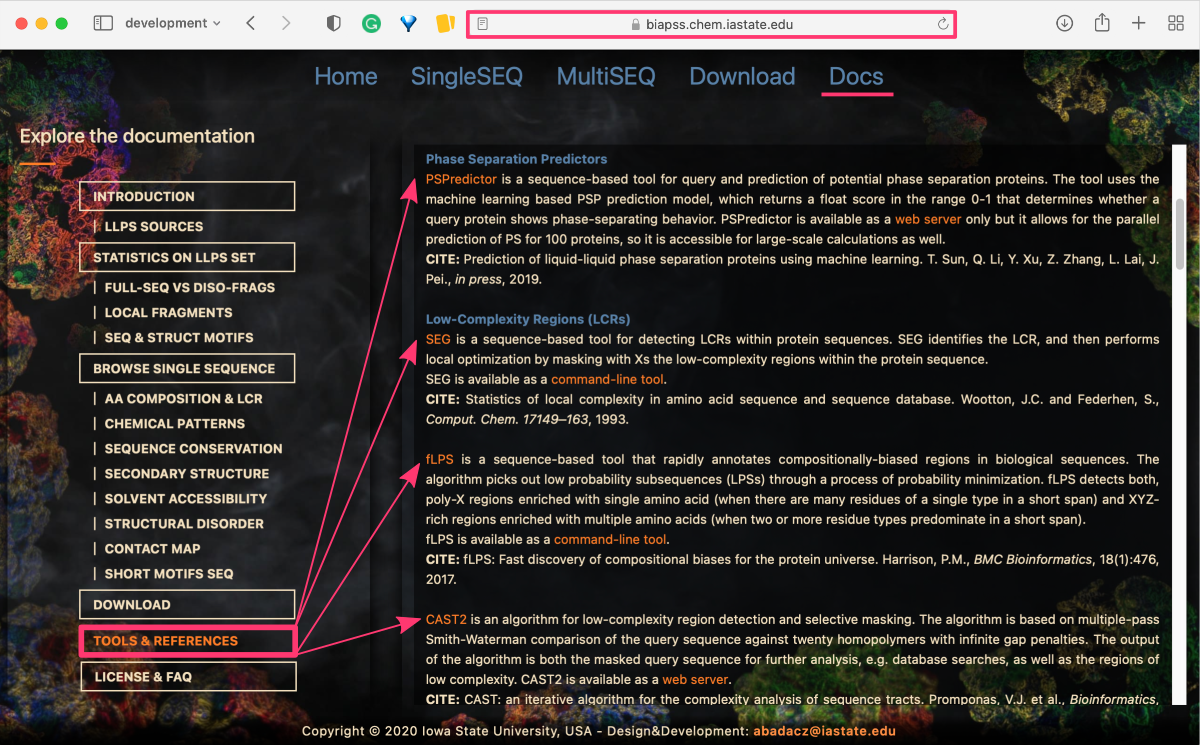
STEP 2. Use developers tools in a browser to find the HTML component with data
It’s important to carefully browse the website and identify the relevant subpage, as this will determine which HTML elements and attributes you need to target during the web scraping process. Once you have located the subpage, you can begin the process of inspecting its HTML structure to identify the elements that contain the desired data.
In this case, right-click on the link for the example tool (e.g., “PSPredictor”) and select Inspect Element from the pop-up dialog box. This will open a separate browser window with the HTML source code of the web page. By default, the code corresponding to the selected text will be highlighted.
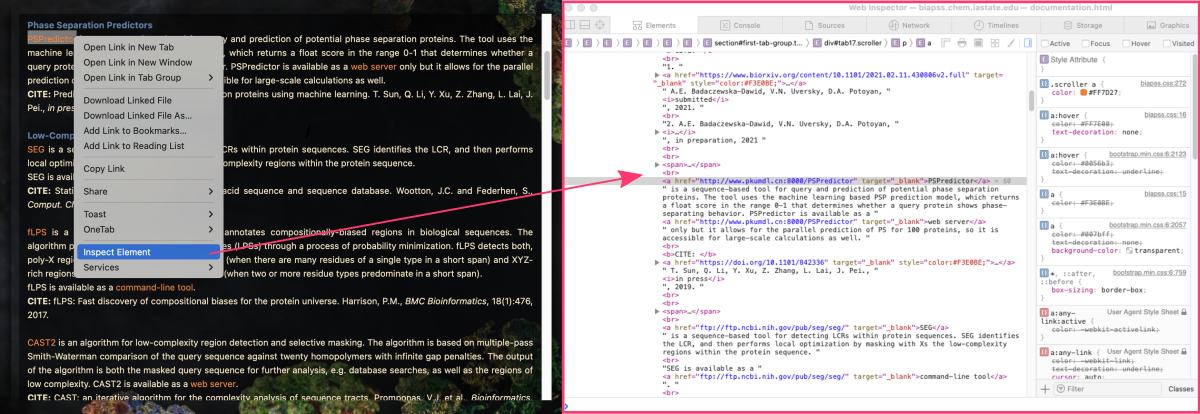
STEP 3. Look for an attribute that is the same for all data elements you want to extract
You will be lucky if the data you want to retrieve is located in regular HTML elements and the web page is well-structured. Regular HTML elements such as paragraphs, headings, tables, and lists are easy to identify and target using web scraping tools like BeautifulSoup or Selenium.
However, not all web pages are well-structured or have data that is easily accessible through regular HTML elements. In some cases, the data may be hidden behind more complex JavaScript code.
In this case, the data we want to derive is located in a regular HTML components <a>Tool Name</a> used to hyperlink the text. You can notice several more links tags in between but only software links are preceded by a single <br> tag. Such a seemingly small element but distributed regularly increases the technical structure of the code and its identification can significantly facilitate data retrieval. However, it would be even simpler if this group of links had a specific HTML class attribute assigned to it.
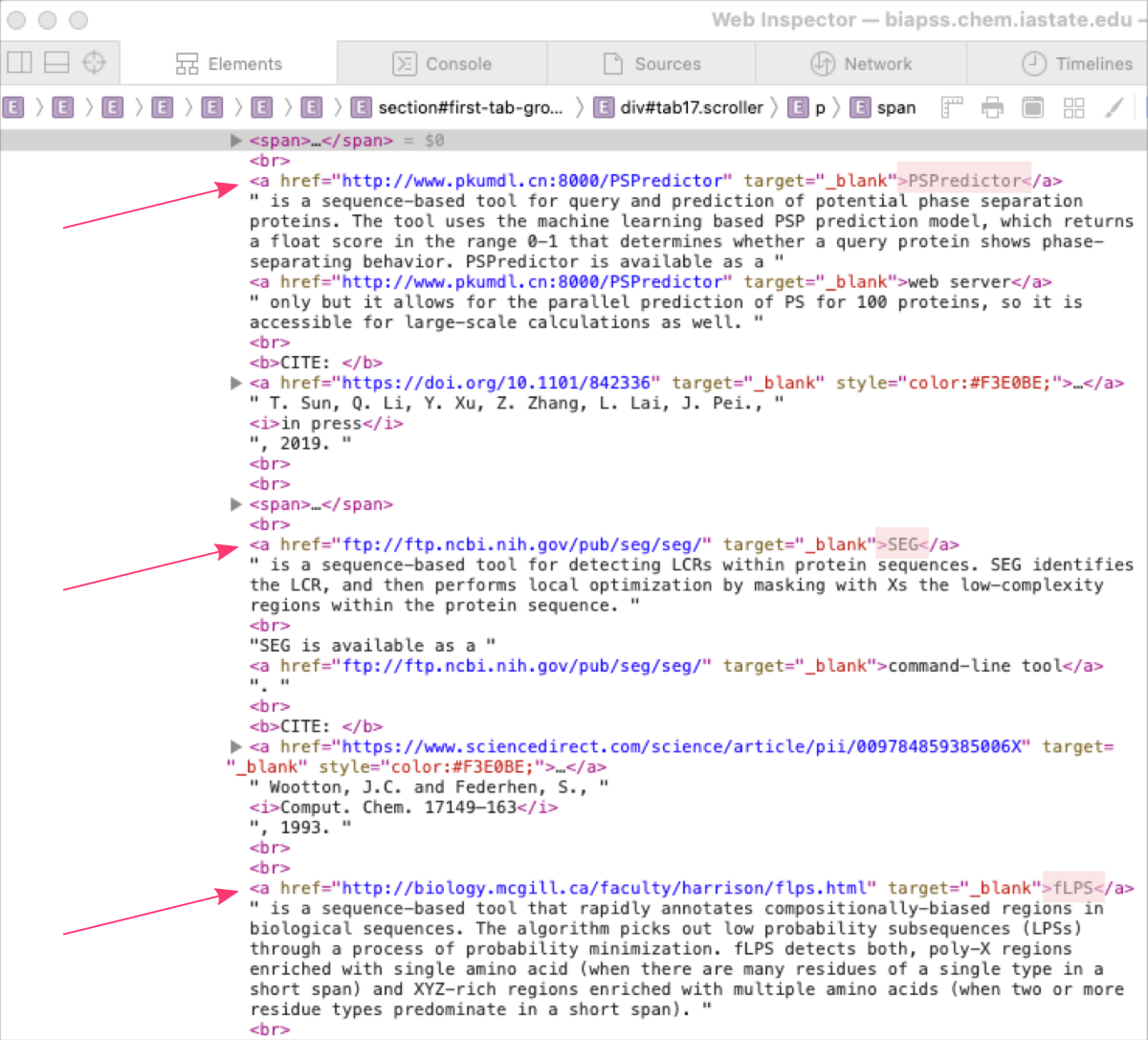
STEP 4. Since the site can be scraped, create a dedicated script
Once you assessed the website is feasible to scrape, you can start developing a dedicated web scraping script. This script will be tailored to this specific website and the data that we want to extract. Also, it’s essential to monitor the website for changes and update the web scraping script accordingly to ensure that it continues to work effectively if you want to retrieve the data updates regularly.
It’s important to note that this script is likely not to be transferable to other websites or pages, as the structure of the HTML and the location of the relevant data will likely differ from site to site. Additionally, the website may be updated or changed by its developers, causing the web scraping script to become outdated and ineffective.
This step assumes you have the web scraping software installed!
For this exercise, you need: python3, selenium, webdriver_manager.
STEP A: Retrieve software names and corresponding URLs
SCRIPT file: scrap_biapps_web_service.py
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
driver.get('https://biapss.chem.iastate.edu/documentation.html')
content = driver.find_elements(By.ID, 'tab17')[0]
DATA = {}
tool = ''
for i in content.find_elements(By.TAG_NAME, 'a'):
if len(i.get_attribute("textContent").split()) < 2:
tool = i.get_attribute("textContent")
DATA[tool] = i.get_attribute("href")
print("\n\nTOOL : URL\n")
for i in DATA:
print(i, ":", DATA[i])
What the script does?
-
Create a Python script file, e.g.,
scrap_biapps_web_service.py - Import all necessary libraries
from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.chrome.service import Service from webdriver_manager.chrome import ChromeDriverManager - Activate the webdriver for your web browser. In this example, we use the Chrome browser, but you can adjust the script for other supported browsers, including Edge, Firefox, IE, and Safari. [ learn more at selenium.dev ⤴]
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install())) - Send a request to the website and get the WebElement with the text content you want to retrieve.
In this example we want to find an HTML element with anID='tab17'. We know which ID it is because we have identified this element in the developer’s tool ‘Inspect Element’ as an external container where descriptions of all software are stored (see steps 2 and 3 above).
This step returns a list of WebElements that match the query. Since only one ‘tab17’ exists, the first element [0] on the list (in Python, indexing starts from 0) is what we want.driver.get('https://biapss.chem.iastate.edu/documentation.html') content = driver.find_elements(By.ID, 'tab17')[0]print(content) <selenium.webdriver.remote.webelement.WebElement (session="0f69ba1669a5c18cc0b93d4313a10f8a", element="f.8A907391AAF7D1548417A3592D33ED12.d.CAE2DB9FF9CBDF9D6F2963AB3D40E3D4.e.2312")>You can find elements on the website by several HTML attributes, including:
ID, NAME, XPATH, LINK_TEXT, PARTIAL_LINK_TEXT, TAG_NAME, CLASS_NAME, and CSS_SELECTOR.
[ learn more at selenium-python.readthedocs.io ⤴] - From the content, select all WebElements that are a link using (By.TAG_NAME, ‘a’) query and parse these elements to extract the
textContent(tool name) andhrefattribute (tool link) of all the software with the one-word tool name.
Since the page text contains many more links, not only for tools’ source code (single orange words) but also for related publications (pale yellow publication titles), we first filter out all links that havetextContentof the link longer than a single word. Then for every record, we add an entry to the DATA dictionary where the key is the tool name, and the value is the URL (i.e., href attribute).DATA = {} tool = '' for i in content.find_elements(By.TAG_NAME, 'a'): if len(i.get_attribute("textContent").split()) < 2: tool = i.get_attribute("textContent") DATA[tool] = i.get_attribute("href") - Finally, we print the DATA dictionary to display the retrieved information on the screen in the format TOOL : URL.
print("\n\nTOOL : URL\n") for i in DATA: print(i, ":", DATA[i])
Run script in the terminal:
python scrap_biapps_web_service.py
TOOL : URL PSPredictor : http://www.pkumdl.cn:8000/PSPredictor SEG : ftp://ftp.ncbi.nih.gov/pub/seg/seg/ fLPS : http://biology.mcgill.ca/faculty/harrison/flps.html CAST2 : http://structure.biol.ucy.ac.cy/CAST2/help.html SIMPLE : https://github.com/john-hancock/SIMPLE-V6 HMMER3.3 : http://hmmer.org/ PSIPRED : http://bioinf.cs.ucl.ac.uk/psipred/ RAPTOR-X : http://raptorx.uchicago.edu/ PORTER-5 : http://distilldeep.ucd.ie/porter/ SPIDER-3 : https://sparks-lab.org/server/spider3/ FESS : http://protein.bio.unipd.it/fells/ PaleAle5.0 : http://distilldeep.ucd.ie/paleale/quickhelp.html SPOT-1D : https://sparks-lab.org/server/spot-1d/ IUPred2A : https://iupred2a.elte.hu/ DISOPRED3 : http://bioinf.cs.ucl.ac.uk/web_servers/psipred_server/disopred_overview/ SPOT-Disorder2 : https://sparks-lab.org/server/spot-disorder/ VSL2 : http://www.dabi.temple.edu/disprot/readmeVSL2.htm PONDR : http://www.pondr.com/ PONDR-FIT : http://original.disprot.org/pondr-fit.php RAPTORX-Contact : http://raptorx.uchicago.edu/ ResPRE : https://zhanglab.ccmb.med.umich.edu/ResPRE/ SPOT-Contact : https://sparks-lab.org/server/spot-contact/ ELM : http://elm.eu.org/elms LARKS : https://science.sciencemag.org/content/359/6376/698 GAR : https://doi.org/10.1016/j.jmb.2018.06.014 phosphosites : https://doi.org/10.3390/ijms20215501
STEP B: Retrieve publications with URLs and match them with the tools
For step B, you can either modify the existing script (scrap_biapps_web_service.py), create a new one (scrap_biapps_web_service_complete.py) or initiate an interactive Python session in the terminal by entering python command and pasting all code snippets there.
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
driver.get('https://biapss.chem.iastate.edu/documentation.html')
content = driver.find_elements(By.ID, 'tab17')[0]
Having the code snippet (above) for the driver and content, we can add next sections in the Python script to:
- create a list of publications
- match publications with a corresponding tool
## Create list of publications
elements = content.get_attribute("innerHTML").split('<br><br>')
to_remove = ['<b>', '</b>', '<i>', '</i>', '<p>', '</p>', '\t', '</a>', 'target="_blank"', 'style="color:#F3E0BE;"']
citations = []
for e in elements:
if "CITE:" in e:
elem = e.split("CITE:")[-1]
for tag in to_remove:
elem = elem.replace(tag, '')
elem = ' '.join(elem.split()).split('<br>')
for cite in elem:
if "href" in cite:
citations.append(cite.split('href=')[1])
What the script does?
As you notice, we add the block of code just below the content that stores the contents of the right panel of the documentation tab of the BIAPSS website once the “Tools & References” button (in the menu of the left panel) is clicked. The task is to retrieve publication records with corresponding links and keep them on the list as clean records (i.e., with all HTML tags removed).
An example elem should look like this:
print(elements[2])
<br><b>CITE: </b> <a href="https://www.sciencedirect.com/science/article/pii/009784859385006X" target="_blank" style="color:#F3E0BE;">
Statistics of local complexity in amino acid sequence and sequence database.</a>
Wootton, J.C. and Federhen, S., <i>Comput. Chem. 17149–163</i>, 1993.
And, opertations in the loops transform the above to get the below:
print(citations[2]) "https://www.sciencedirect.com/science/article/pii/009784859385006X" : Statistics of local complexity in amino acid sequence and sequence database. Wootton, J.C. and Federhen, S., Comput. Chem. 17149–163, 1993.
How to do that?
- First, transform the WebElement object to plain HTML code (i.e., get website textContent while keeping all innerHTML tags). We need this form of content to extract URLs (HTML href attribute) to the publications which are not visible in the website interface (i.e., textContent). However, this means we must remove all unnecessary HTML tags stored in the to_remove list, to get cleansed publication records.
elements = content.get_attribute("innerHTML").split('<br><br>') to_remove = ['<b>', '</b>', '<i>', '</i>', '<p>', '</p>', '\t', '</a>', 'target="_blank"', 'style="color:#F3E0BE;"']Now, elements is a list of text strings full of various HTML tags (see to_remove list). Each string on the list corresponds to the single tool and may look like this:
print(elements[2]) <span><b>Low-Complexity Regions (LCRs)</b></span> <br><a href="ftp://ftp.ncbi.nih.gov/pub/seg/seg/" target="_blank">SEG</a> is a sequence-based tool for detecting LCRs within protein sequences. SEG identifies the LCR, and then performs local optimization by masking with Xs the low-complexity regions within the protein sequence. <br>SEG is available as a <a href="ftp://ftp.ncbi.nih.gov/pub/seg/seg/" target="_blank">command-line tool</a>. <br><b>CITE: </b> <a href="https://www.sciencedirect.com/science/article/pii/009784859385006X" target="_blank" style="color:#F3E0BE;"> Statistics of local complexity in amino acid sequence and sequence database.</a> Wootton, J.C. and Federhen, S., <i>Comput. Chem. 17149–163</i>, 1993. - We will use Python to parse these text strings to extract clear
URL : PUBLICATIONrecords.for e in elements: if "CITE:" in e: elem = e.split("CITE:")[-1]While iterating elements:
- first, select only those that contain the “CITE:” keyword
- then split the string by this keyword and keep only the last [-1] part of the string, i.e., the part corresponding to publications.
print(elem) </b> <a href="https://www.sciencedirect.com/science/article/pii/009784859385006X" target="_blank" style="color:#F3E0BE;"> Statistics of local complexity in amino acid sequence and sequence database.</a> Wootton, J.C. and Federhen, S., <i>Comput. Chem. 17149–163</i>, 1993.
This part of the string is stored in the
elemvariable now.Remove all HTML tags from it by iterating the to_removelist:for tag in to_remove: elem = elem.replace(tag, '')You should get something like this:
print(elem) <a href="https://www.sciencedirect.com/science/article/pii/009784859385006X" > Statistics of local complexity in amino acid sequence and sequence database. Wootton, J.C. and Federhen, S., Comput. Chem. 17149–163, 1993.
- In the next step, we replace multiple white characters with a single space and split by
<br>publications for a single tool to create a separate record for each. Now, theelembecomes a list of individual publication records.elem = ' '.join(elem.split()).split('<br>')print(elem) ['<a href="https://www.sciencedirect.com/science/article/pii/009784859385006X" > Statistics of local complexity in amino acid sequence and sequence database. Wootton, J.C. and Federhen, S., Comput. Chem. 17149–163, 1993.']
- Finally, once we make sure the publication record contains an HTML attribute
hrefstoring the URL, we append such a record to the citation list, which will be used later to match publication records with a tool.for cite in elem: if "href" in cite: citations.append(cite.split('href=')[1])print(elem) '"https://www.sciencedirect.com/science/article/pii/009784859385006X" > Statistics of local complexity in amino acid sequence and sequence database. Wootton, J.C. and Federhen, S., Comput. Chem. 17149–163, 1993.'
So, we have publications with URLs sored in the citations list. And, we also have the previously created code snippet that creates dictionary DATA with tools as keys:
DATA = {}
tool = ''
for i in content.find_elements(By.TAG_NAME, 'a'):
if len(i.get_attribute("textContent").split()) < 2:
tool = i.get_attribute("textContent")
DATA[tool] = [i.get_attribute("href"), []]
Below, we insert a condition within the same for loop that will match the publictation to the tool:
## Match Publications with a tool
elif tool != '':
cite = ' '.join(i.get_attribute("textContent").split())
for item in citations:
if cite in item and item not in DATA[tool][1]:
DATA[tool][1].append(item)
break
What the script does?
While iterating over all links in the page content, once the textContent does not correspond to the tool, it is considered a publication record, parsed in the elif statement. First, we take the textContent and create the cleansed string stored in the cite variable to use as a search query in the citation list. Once found, the matching item from the citation list is added as a second field DATA[tool][1] in the value of the tool key in the DATA dictionary.
Now you are ready to print on the screen all data retrieved in the new format: TOOL : URL : PUBLICATIONS.
print("\n\nTOOL : URL : PUBLICATIONS\n")
for i in DATA:
print('\n', i, ":", DATA[i][0])
for j in DATA[i][1]:
print(" - ", j.replace('>', ': '))
Run in the terminal:
python scrap_biapps_web_service_complete.py
see the complete script... (if necessary))
SCRIPT file: scrap_biapps_web_service_complete.py
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
driver.get('https://biapss.chem.iastate.edu/documentation.html')
content = driver.find_elements(By.ID, 'tab17')[0]
## Create list of publications
elements = content.get_attribute("innerHTML").split('<br><br>')
to_remove = ['<b>', '</b>', '<i>', '</i>', '<p>', '</p>', '\t', '</a>', 'target="_blank"', 'style="color:#F3E0BE;"']
citations = []
for e in elements:
if "CITE:" in e:
elem = e.split("CITE:")[-1]
for tag in to_remove:
elem = elem.replace(tag, '')
elem = ' '.join(elem.split()).split('<br>')
for cite in elem:
if "href" in cite:
citations.append(cite.split('href=')[1])
DATA = {}
tool = ''
for i in content.find_elements(By.TAG_NAME, 'a'):
if len(i.get_attribute("textContent").split()) < 2:
tool = i.get_attribute("textContent")
DATA[tool] = [i.get_attribute("href"), []]
## Match Publications with a tool
elif tool != '':
cite = ' '.join(i.get_attribute("textContent").split())
for item in citations:
if cite in item and item not in DATA[tool][1]:
DATA[tool][1].append(item)
break
print("\n\nTOOL : URL : PUBLICATIONS\n")
for i in DATA:
print('\n', i, ":", DATA[i][0])
for j in DATA[i][1]:
print(" - ", j.replace('>', ': '))
TOOL : URL : PUBLICATIONS PSPredictor : http://www.pkumdl.cn:8000/PSPredictor - "https://doi.org/10.1101/842336" : Prediction of liquid-liquid phase separation proteins using machine learning. T. Sun, Q. Li, Y. Xu, Z. Zhang, L. Lai, J. Pei., in press, 2019. SEG : ftp://ftp.ncbi.nih.gov/pub/seg/seg/ - "https://www.sciencedirect.com/science/article/pii/009784859385006X" : Statistics of local complexity in amino acid sequence and sequence database. Wootton, J.C. and Federhen, S., Comput. Chem. 17149–163, 1993. fLPS : http://biology.mcgill.ca/faculty/harrison/flps.html - "https://bmcbioinformatics.biomedcentral.com/articles/10.1186/s12859-017-1906-3" : fLPS: Fast discovery of compositional biases for the protein universe. Harrison, P.M., BMC Bioinformatics, 18(1):476, 2017. CAST2 : http://structure.biol.ucy.ac.cy/CAST2/help.html - "https://academic.oup.com/bioinformatics/article/16/10/915/223582" : CAST: an iterative algorithm for the complexity analysis of sequence tracts. Promponas, V.J. et al., Bioinformatics, 16(10), 915–922, 2000. [...]
Further Reading
Downloading online repos using GIT: [GitHub, Bitbucket, SourceForge]Downloading a single folder or file from GitHub
Remote data preview (without downloading)
Viewing text files using UNIX commands
Viewing PDF and PNG files using X11 SSH connection
Viewing graphics in a terminal as the text-based ASCII art
Mounting remote folder on a local machine
Data manipulation
Data wrangling: use ready-made apps
MODULE 08: Data Visualization