
Introduction
You can find the official SciPy documentation on their website at: https://docs.scipy.org/doc/scipy/tutorial/index.html ⤴
SciPy ⤴ is a Python library for scientific and technical computing that provides a collection of algorithms and functions for tasks such as optimization, signal processing, linear algebra, and more. It is built on top of NumPy ⤴, another popular Python library for numerical computing, and is a fundamental tool for data analysis and scientific computing.
The library is open-source and free to use, with a large community of contributors who are continuously adding new features and improving existing ones. Additionally, SciPy works well with other popular scientific computing libraries, such as Matplotlib and Pandas, making it a valuable tool for data scientists and researchers in various fields.
Getting started with SciPy
SciPy is NOT a built-in Python module, meaning it is not included with the standard Python distribution. It is an external library that can be installed and imported into a Python environment.
Install scipy library
To install SciPy, you can use pip, which is the standard package installer for Python. You can run the following command in your terminal or command prompt to install SciPy:
pip install scipy
This will download and install the latest version of SciPy from the Python Package Index (PyPI).
An alternative way to install SciPy is using Conda. This way you can install different variants of scipy library in separate virtual environments, depending on the requirements of your project. You can create and activate a new conda environment, and then install scipy libarary:
conda install scipy
This will download and install the latest version of SciPy from the conda repository.
This command will install scipy and any necessary dependencies in your current Conda environment. conda installed yet, you can follow the guide provided in the tutorial . If you are using the Anaconda distribution, conda is already installed by default.
conda provides additional benefits over pip, such as the ability to create and manage multiple environments for different projects with different dependencies, and the ability to install packages from both the Conda and PyPI (Python Package Index) repositories.
If you are working in a virtual environment, you can install packages without administrative privileges by activating the virtual environment before running the installation command.
Import scipy library
Once installed, SciPy can be imported into Python scripts and used to perform numerical computations and data manipulation.
import scipy as sp
This will import the SciPy library and give it an alias of sp, which is a commonly used abbreviation for SciPy.
You can then use the SciPy functions and classes in your code by prefixing them with sp, such as sp.array() or sp.stats.norm.
Import methods from submodules
To import selected methods from SciPy submodules, you can use the from ... import ... syntax.
For example, to import the linalg.solve method from the scipy.linalg submodule, you can use the following code:
from scipy.linalg import solve
After importing the method in this way, you can use it directly in your code without the need to prefix it with the submodule name, as shown below:
import numpy as np
from scipy.linalg import solve
A = np.array([[1, 2], [3, 4]])
b = np.array([5, 6])
x = solve(A, b) # use imported method directly
print(x)
In this example, we import the solve method from scipy.linalg and then use it to solve a system of linear equations.
print(x) [-4. 4.5]
Submodules in SciPy
The SciPy library contains several submodules that cater to specific scientific domains. Each submodule offers a range of specialized functionalities that can help you solve a wide variety of scientific and technical computing problems.
| submodule | description | documentation |
|---|---|---|
| scipy.io | Contains functions for reading and writing data in various file formats, such as MATLAB, NetCDF, and WAV. | docs ⤴ |
| scipy.datasets | Provides a selection of datasets for use in scientific and statistical analysis, such as iris and MNIST. | docs ⤴ |
| scipy.constants | Contains physical and mathematical constants, such as the speed of light and the golden ratio. | docs ⤴ |
| scipy.stats | Contains a range of statistical functions, including probability distributions, descriptive statistics, hypothesis testing, and regression analysis. | docs ⤴ |
| scipy.cluster | Offers algorithms for clustering data, including k-means, hierarchical clustering, and spectral clustering. | docs ⤴ |
| scipy.optimize | Contains various optimization algorithms for minimizing or maximizing functions, including nonlinear least squares, least-squares minimization, and root finding. | docs ⤴ |
| scipy.interpolate | Provides functions for interpolating 1D and higher-dimensional data, including splines, radial basis functions, and smoothing. | docs ⤴ |
| scipy.integrate | Provides functions for numerical integration, including single and multi-dimensional integration, as well as ODE solvers. | docs ⤴ |
| scipy.linalg | Contains linear algebra functions, including matrix operations, eigenvalue problems, and decompositions. | docs ⤴ |
| scipy.fftpack | Provides functions for computing fast Fourier transforms (FFT) and related operations. | docs ⤴ |
| scipy.odr | Offers orthogonal distance regression (ODR) for fitting models to data with errors in both the x and y dimensions. | docs ⤴ |
| scipy.sparse | Provides tools for working with sparse matrices, including operations such as matrix multiplication, linear solvers, and eigenvalue problems. | docs ⤴ |
| scipy.spatial | Provides functions for working with spatial data, including distance calculations, nearest-neighbor searches, and Voronoi diagrams. | docs ⤴ |
| scipy.signal | Offers a range of signal processing functions, including filtering, Fourier analysis, wavelets, and convolution. | docs ⤴ |
| scipy.ndimage | Provides functions for n-dimensional image processing and filtering, such as smoothing, edge detection, and morphology. | docs ⤴ |
| scipy.special | Contains special functions, such as Bessel functions, gamma functions, and error functions. | docs ⤴ |
| scipy.misc | Offers various utility functions for scientific computing, such as image manipulation and numerical approximations. | docs ⤴ |
scipy.io
The scipy.io module provides functions for reading and writing data in various file formats. Some of the most common functions in this module are:
loadmat()- oad data from MATLAB .mat filessavemat()- save data to a MATLAB .mat file
Other I/O functions refer to IDL files, Matrix Market files, Unformatted Fortran files, Netcdf, Harwell-Boeing files, Wav sound files, and Arff files. Learn more from the official documentation: scipy.io ⤴.
| savemat() | loadmat() |
|---|---|
|
|
| It takes a dictionary of variables and their values as input. | It returns a dictionary containing the variables and their values. |
import scipy.io as sio
import numpy as np
data = {'x': np.array([1, 2, 3]), 'y': np.array([4, 5, 6])} # create data sample
sio.savemat('data.mat', data) # save data to .mat file
data = sio.loadmat('data.mat') # load data from .mat file
print(data.keys()) # output: ['x', 'y']
print(data['x']) # output: [][1 2 3]]
In this example, we create a dictionary data that contains two arrays, x and y. We then use the savemat() function to save the data to a MATLAB .mat file called data.mat. Then, we use the loadmat function to load data from a MATLAB .mat file called data.mat. We print the keys of the dictionary that is returned by the function to see the variables that were loaded, and then we print the value of the x variable.
scipy.datasets
The scipy.datasets module provides a set of 3 datasets that can be used for testing, benchmarking, and other purposes:
ascent()- grayscale imageface()- color imageelectrocardiogram()- medical recordings of the heart’s electrical activity
The module provides a set of built-in functions to load these datasets by their names.
import scipy
data = scipy.datasets.ascent()
print(data) [[ 83 83 83 ... 117 117 117] [ 82 82 83 ... 117 117 117] [ 80 81 83 ... 117 117 117] ... [178 178 178 ... 57 59 57] [178 178 178 ... 56 57 57] [178 178 178 ... 57 57 58]]
If you want to download all datasets included in Scipy, you can use the download_all() function. This function will download all three datasets and save them to a selected location as .dat files.
from scipy.datasets import download_all
download_all('.', subok=True)
In this code, download_all() will download the three datasets to the current working directory, represented by '.'. The subok=True parameter ensures that any subdirectories needed to save the files will be created if they don’t already exist.
…from the official documentation: scipy.datasets ⤴.
scipy.constants
The scipy.constants module provides a collection of physical and mathematical constants. These constants are often used in scientific calculations and simulations. The full list of available constants can be explored in the official documentation: scipy.constants ⤴
Here are some of the most commonly used methods in this module along with their usage examples:
- scipy.constants.value(constant_name)
Returns the numerical value of a given physical constant.
from scipy import constants
constants.value('Planck constant')
6.62607015e-3
Some common constants, such as R (molar gas constant), C (speed of light in vacuum), g (standard acceleration due to gravity), or atomic mass, can be called directly by their symbol or name:
from scipy import constants
constants.c # output: 299792458.0
constants.g # output: 9.80665
constants.R # output: 8.31446261815324
constants.atomic_mass # output: 1.6605390666e-27
- scipy.constants.find(substring)
Returns a list of constants whose names contain the given substring.
from scipy import constants
constants.find('Planck')
['Planck constant', 'Planck constant in eV/Hz', 'Planck length', 'Planck mass', 'Planck mass energy equivalent in GeV', 'Planck temperature', 'Planck time', 'molar Planck constant', 'reduced Planck constant', 'reduced Planck constant in eV s', 'reduced Planck constant times c in MeV fm']
scipy.constants.physical_constants[constant_name]
Returns a tuple containing the value, unit, and uncertainty of a given physical constant.
from scipy import constants
constants.physical_constants['proton mass'] # output: (1.67262192369e-27, 'kg', 5.1e-37)
(1.67262192369e-27, 'kg', 5.1e-37)
- scipy.constants.unit(constant_name)
Returns the unit of a given physical constant.
from scipy import constants
constants.unit['proton mass'] # output: 'kg'
- scipy.constants.convert_temperature(temp, from_unit, to_unit)
Returns the unit of a given physical constant.
from scipy import constants
constants.convert_temperature(100, 'Celsius', 'Kelvin') # output: 373.15
scipy.stats
The scipy.stats module provides a wide range of distributions, including:
- Probability distributions ⤴
- Continuous distributions ⤴
- Multivariate distributions ⤴
- Discrete distributions ⤴
- Distribution Fitting ⤴
- Random variate generation / CDF Inversion ⤴
and statistical functions:
- Summary statistics ⤴
- Frequency statistics ⤴
- Statistical tests ⤴
- Correlation functions ⤴
- Directional statistical functions ⤴
- Statistical distances ⤴
- Masked statistics functions ⤴
and other statistical functionality such as Transformations ⤴, Sampling ⤴, Resampling Methods ⤴, Quasi-Monte Carlo ⤴ and stats-specific Warnings / Errors ⤴.
Here are a few common methods with usage examples:
generate random samples
A. Returns a normal continuous random variable:
scipy.stats.norm
Here’s an example of generating 10 random samples from a normal distribution with a mean of 0 and a standard deviation of 1:
from scipy.stats import norm
data = norm.rvs(size=10)
data
array([-0.78903894, -1.55293905, -0.64965826, -1.05128015, 2.55342981,
-0.2064151 , -0.60322765, -0.861767 , -0.75899174, -1.28693063])
print(data)
[-0.78903894 -1.55293905 -0.64965826 -1.05128015 2.55342981 -0.2064151
-0.60322765 -0.861767 -0.75899174 -1.28693063]
B. Returns a binomial discrete random variable:
scipy.stats.binom
Here’s an example of generating 10 random samples from a binomial distribution with 10 trials and a success probability of 0.5:
from scipy.stats import binom
data = binom.rvs(n=10, p=0.5, size=10)
print(data) [2 4 4 5 5 7 6 6 3 5]
C. Returns a chi-squared continuous random variable:
scipy.stats.chi2
Here’s an example of generating 10 random samples from a chi-squared distribution with 2 degrees of freedom:
from scipy.stats import chi2
data = chi2.rvs(df=2, size=10)
print(data) [1.04467704 1.1461272 0.36506538 0.81107591 3.26317094 4.84727761 4.52965288 0.93817042 8.51668502 3.2564631 ]
D. Returns a gamma continuous random variable:
scipy.stats.gamma
Here’s an example of generating 10 random samples from a gamma distribution with a shape parameter of 2 and a scale parameter of 2:
from scipy.stats import gamma
data = gamma.rvs(a=2, scale=2, size=10)
print(data) [ 0.80623887 3.61599447 4.67765372 3.27401918 4.62340971 4.33309687 1.51408293 1.31255128 3.13450136 10.43018603]
calculate T-test of one sample
scipy.stats.ttest_1samp
Calculates the T-test for the mean of one sample.
Here’s an example of performing a one-sample T-test on a set of data:
from scipy.stats import ttest_1samp
data = [1, 2, 3, 4, 5]
ttest_1samp(data, 3)
TtestResult(statistic=0.0, pvalue=1.0, df=4
calculate ANOVA test for multiple samples
scipy.stats.f_oneway
Performs a one-way ANOVA test for multiple samples.
Here’s an example of performing an ANOVA test on three sets of data:
from scipy.stats import f_oneway
data1 = [1, 2, 3, 4, 5]
data2 = [2, 4, 6, 8, 10]
data3 = [3, 6, 9, 12, 15]
f_oneway(data1, data2, data3)
F_onewayResult(statistic=3.857142857142857, pvalue=0.05086290933139865)
calculate a Pearson correlation coefficient
scipy.stats.pearsonr
Calculates a Pearson correlation coefficient and the associated p-value.
Here’s an example of calculating the correlation coefficient between two sets of data:
from scipy.stats import pearsonr
x = [1, 2, 3, 4, 5]
y = [2, 4, 6, 8, 10]
pearsonr(x, y)
PearsonRResult(statistic=1.0, pvalue=0.0)
calculate a linear least-squares regression
scipy.stats.linregress
Calculates a linear least-squares regression for two sets of measurements.
Here’s an example of performing a linear regression on two sets of data:
from scipy.stats import linregress
x = [1, 2, 3, 4, 5]
y = [2, 4, 6, 8, 10]
linregress(x, y) # output: LinregressResult(slope=2.0, intercept=0.0, rvalue=1.0, pvalue=1.2004217548761408e-30, stderr=0.0, intercept_stderr=0.0)
LinregressResult(slope=2.0, intercept=0.0, rvalue=1.0, pvalue=1.2004217548761408e-30, stderr=0.0, intercept_stderr=0.0)
scipy.cluster
The scipy.cluster module of Scipy provides algorithms for clustering, which involves grouping data points into clusters based on their similarities. The full list of available clustering methods can be explored in the official documentation: scipy.cluster ⤴
Here are some of the most common methods in this module along with usage examples:
hierarchical clustering with linkage matrix
scipy.cluster.hierarchy.linkage
Computes the hierarchical clustering of a dataset and returns a linkage matrix.
import numpy as np
from scipy.cluster.hierarchy import linkage
data = np.random.rand(5, 3)
linkage_matrix = linkage(data, method='single')
see the expected output
print(data) [[0.97309739 0.14092786 0.73237976] [0.53102418 0.85463043 0.28841557] [0.25546178 0.51738497 0.28659921] [0.7780539 0.35929428 0.53852367] [0.60161033 0.82559442 0.34248004]] print( linkage_matrix) [[1. 4. 0.09353321 2. ] [0. 3. 0.3511496 2. ] [2. 5. 0.43551399 3. ] [6. 7. 0.53572498 5. ]]
Check if a linkage matrix is valid
scipy.cluster.hierarchy.is_valid_linkage
Here’s an example of using this method:
from scipy.cluster.hierarchy import is_valid_linkage
print(is_valid_linkage(linkage_matrix)) # output: True
Get leaf nodes of a hierarchical clustering
scipy.cluster.hierarchy.leaves_list
Returns the leaf nodes of a hierarchical clustering.
from scipy.cluster.hierarchy import leaves_list
leaves = leaves_list(linkage_matrix)
print(leaves) [0 3 2 1 4]
hierarchical clustering as a dendrogram
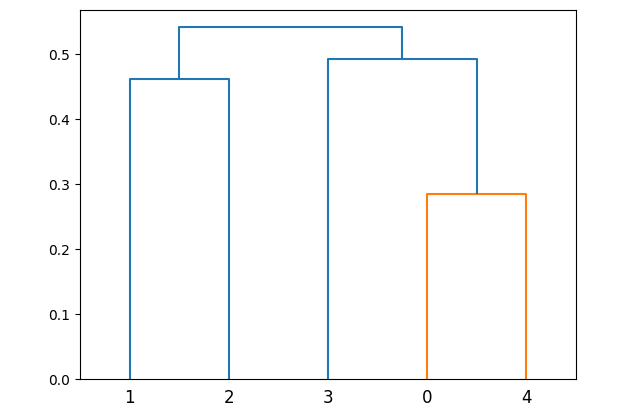
scipy.cluster.hierarchy.dendrogram
Plots the hierarchical clustering as a dendrogram.
import numpy as np
import matplotlib.pyplot as plt
from scipy.cluster.hierarchy import linkage, dendrogram
data = np.random.rand(5, 3)
linkage_matrix = linkage(data, method='single')
dendrogram(linkage_matrix)
plt.show()
dendrogram(linkage_matrix)
{'icoord': [[5.0, 5.0, 15.0, 15.0], [35.0, 35.0, 45.0, 45.0], [25.0, 25.0, 40.0, 40.0], [10.0, 10.0, 32.5, 32.5]],
'dcoord': [[0.0, 0.4609265621656883, 0.4609265621656883, 0.0], [0.0, 0.28518916147512924, 0.28518916147512924, 0.0], [0.0, 0.491984094759486, 0.491984094759486, 0.28518916147512924], [0.4609265621656883, 0.5412089099877605, 0.5412089099877605, 0.491984094759486]],
'ivl': ['1', '2', '3', '0', '4'],
'leaves': [1, 2, 3, 0, 4],
'color_list': ['C0', 'C1', 'C0', 'C0'],
'leaves_color_list': ['C0', 'C0', 'C0', 'C1', 'C1']
}
plt.show()
k-means clustering with centroids
scipy.cluster.vq.kmeans
Performs k-means clustering on a dataset and returns the cluster centroids.
import numpy as np
from scipy.cluster.vq import kmeans
data = np.random.rand(5, 3)
centroids, _ = kmeans(data, 2)
print(centroids) [[0.24676794 0.82368652 0.88983179] [0.6756976 0.53838277 0.16609091]]
Assigns point to the nearest cluster centroid
scipy.cluster.vq.vq
Assigns each data point to the nearest cluster centroid using vector quantization.
from scipy.cluster.vq import vq
labels, _ = vq(data, centroids)
print(labels) [0 0 1 0 1]
Further Reading
Introduction to R programmingBase R - core functionality for statistical computing
Base R Graphics - traditional statistical graphing
ggplot2 - customizable graphs and charts
dplyr - data manipulation and transformation
tidyverse - advanced data manipulation, exploration and visualization
data.table - aggregation and manipulation of large data sets
Introduction to Julia programming
Julia setup: installation, environments and Jupyter integration
MODULE 06: High-Performance Computing (HPC)