
DataScience Workbook / 01. Introduction to Data Science / 1. Data Science Principles
Introduction
1. What is Data?
Data is a collection of observables registered in any form. Commonly, it is a sequence of written characters (numerical or symbolic), audio stream, or visual depiction. The analog signals � have been steadily replaced since the 1960s by digital records �, so today, digital data prevail.
A single item of data is called a datum. Each datum, in a computer-readable representation, has assigned the binary value of “zero” or “one” (corresponding to logical “false” and “true”), resulting in a bit of information, i.e., one binary digit.
Due to the source and size, data may have different structures. The technical construction of the data structure is a significant factor in the computer’s ability to easily access, search, update, and process the data.
1.1. Structured Data
In a nutshell, structured data is highly organized in terms of easy digital deciphering rather than human readability. That includes a standardized format, enduring order, and categorization in a well-determined arrangement that facilitates managing and querying datasets in various combinations. Depending on the intent to use the data, the specific relations between elements are revealing. Structured data is easily serchable.
A typical example of an organized data structure is a spreadsheet or database, generally composed of a data series split into fields and assembled in a pre-defined manner, see table below. Information is categorized by fields that group items by a shared value or defined relation.
Table 1. The dataset contains structured data on several plant species. Item-specific information is assigned to categories denoted by pre-defined fields. [information in this table was taken from the Wikipedia articles for each species]
| FIELDS: | common name | species | kingdom | region | vegetation | flower color | properties |
|---|---|---|---|---|---|---|---|
| ITEM 1 | bitter aloe | Aloe ferox | plantae | South Africa | succulent | red-orange | healing |
| ITEM 2 | ribwort plantain | Plantago lanceolata | plantae | norther globe | perennial | brown | healing |
| ITEM 3 | elderberry | Sambucus nigra | plantae | Europe | shrub | white | healing |
| ITEM 4 | absinthium | Artemisia absinthium | plantae | norther globe | perennial | yellow | healing |
| ITEM 5 | field milk thistle | Sonchus arvensis | plantae | norther globe | perennial | yellow | toxic |
| ITEM 6 | yellow anemone | Anemone ranunculoides | plantae | norther globe | perennial | yellow | toxic |
Examples of well-structured data include transactions in financial systems (customers identities related with their account numbers), online stores (products tagged with the prices), genomic databases (genes linked with the corresponding sequenece), phonebook (names of residents matched with addresses and phone numbers), a hierarchical classification of species of organisms, as well as any data that can be stored in the predefined forms.
Learn more details from Wikipedia: Data model and corresponding references.
Explore also:
★ IBM Cloud Education: Structured vs. Unstructured Data: What’s the Difference?
★ Datamation Education: Structured vs. Unstructured Data
1.2. Unstructured Data
Unstructured data, as defined by itself, has no regular structure that can be easily detected, processed, and categorized by computer algorithms - even though it is easily understood by a human. A good example is the streams of highly varied text contained in emails, social media posts, online blogs, newspapers, books, and scientific publications. The descriptive nature of this data is clear in meaning to humans, but semantic complexity and context are often a limitation for conventional computer programs.
The concept of unstructured data also includes many other formats such as audio and video recording, images and photos, data from various sensors (weather, traffic), medical records combining different forms of diagnostics, and various scientific measurements. This type of data seems as far more raw, massive, and descriptive than structured data. It also requires advanced filtering, pattern searching, and data mining.
Since the computer revolution and especially today, this is the dominant type of data generated and processed, which carries a high potential for the extraction and retention of knowledge. Technological innovations in machine learning and artificial intelligence enable efficient analysis of unstructured data opening new opportunities for science, business, and public health. It also brings many conveniences to everyday life in the 21st century.
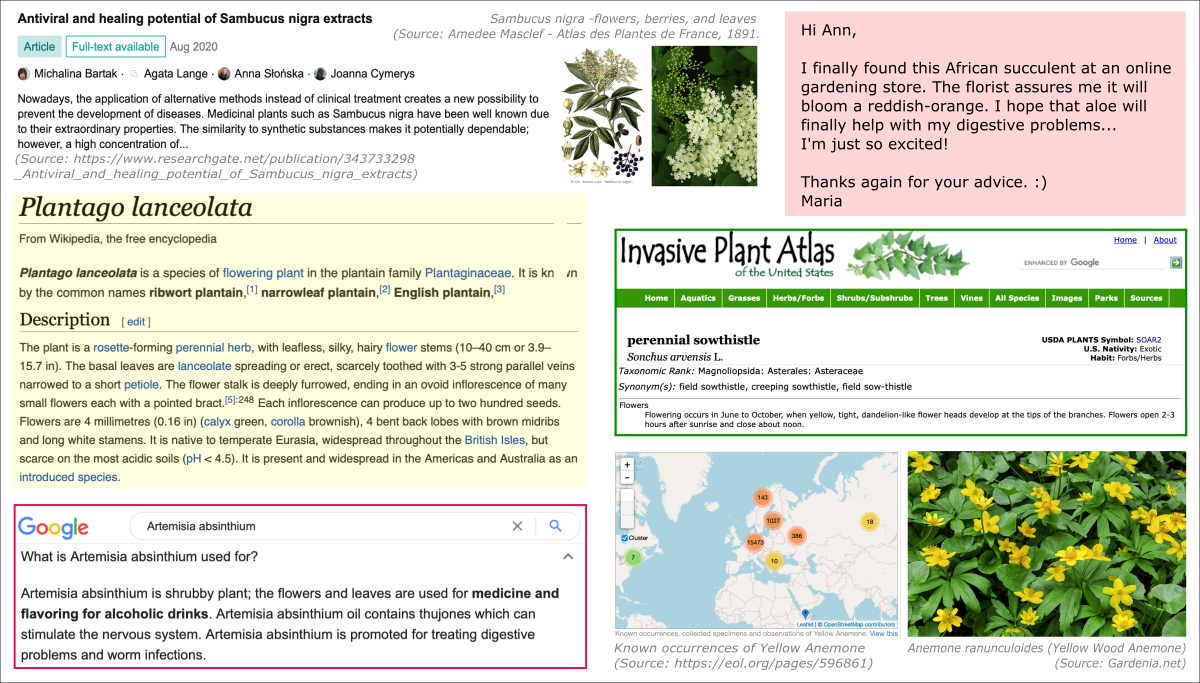
Figure 1. The image shows examples of unstructured data, with content referring to items from the Table 1. [track image sources in the FILE]
Learn more details from Wikipedia: Unstructured Data and corresponding references.
Explore also:
★ IBM Cloud Education: Structured vs. Unstructured Data: What’s the Difference?
★ Datamation Education: Structured vs. Unstructured Data
1.3. Big Data
The Big Data term emerged in the 1990s � with the rapid growth of digital data. The first two decades of the 21st century have dynamically ushered us into the Zettabyte Era �. Thus, the essence of Big Data focuses on the size of data, the volume of which continually expands and becomes a bottleneck on existing computational approaches. You are not wrong guessing that Big Data input is mainly unstructured data.
So, in addition to size, the challenge is the variety and noise nature of such data that no longer fit into the framework of conventional relational databases. It also requires an alternate data-processing software that supports efficient sampling of large datasets within a reasonable time (velocity) and usually requires distributed computing (High-Performance Computing and parallelization of tasks).
The ultimate goal of the conducted analysis is the veracity and value of the extracted information. The retrieved knowledge is then presented in a meaningful way that highlights its significance for the business or breakthrough in science.
Thus, Big Data goes beyond the simple concept of the data type or volume used. It also integrates (i) analytical techniques (e.g., machine learning), (ii) technologies that make it possible (e.g., parallel and cloud computing), and (iii) modern visualization solutions (e.g., interactive graphing and infographics). Big Data processing by applying a specialized combination of scientific approaches (e.g., statistics, mathematics, informatics, and background knowledge in a specific area) has become a significant part of Data Science.
Figure 2. The image shows steps for generating and processing Big Data in the Data Science framework. [track image sources in the FILE]
Learn more details from Wikipedia: Big Data and corresponding references.
Explore also:
★ eduCBA Education: Big Data vs Data Science
2. The Life Cycle of Data
| The life cycle of Big Data goes through 5 major phases: |
Figure 3. The Life Cycle of Data [track image sources in the FILE] |
|---|---|
| • Capturing - Raw Data Acquisition • Maintaining - Data Cleansing & Warehousing • Processing - Data Mining and Information Classification • Analyzing - Statistical Analysis and Knowledge Extraction • Communicating - Knowledge Reporting & Visualization |
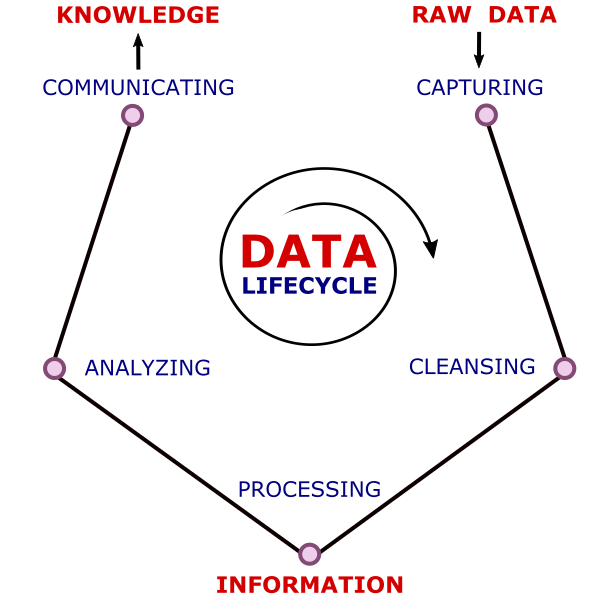 |
During the cycle, the amount of data is reduced by much in favor of densification of value and relevance. Large amounts of raw, usually highly variable data, are first cleansed by filtering. Then the relevant data is mined through pattern search and machine learning. Initial data clustering reveals some relations that are feasible to classify information. At this stage, volumetric data is transformed into valuable information, defined as processed, organized, and structured data. Statistical analysis and combinatorial querying of categorized information enable the discovery of deeply coupled correlations and formulate non-trivial conclusions. That means extracting knowledge. Insights are advantageous when applied successfully, so meaningful communication is critical for knowledge retention and steady development.
2.1. States of Data
Raw Data
Raw Data is the data captured from the source and has not been processed before the use. It usually has a large volume and serves as a primary unfiltered input in Data Science.
Information
Information is a meaningful and organized product of data processing. It maintains data compression, encapsulates densification of value and veracity, and provides context for querying in the analysis.
Knowledge
Knowledge is an extracted non-trivial insight from the data classification and analysis of information that while applied leads to problem-solving, improvements, and steady development.
2.2. Data Operations
Storage - Data at Rest
Data at rest is digital data physically retained on computer storage in various forms, including data warehouses and file hosting services, databases and spreadsheets, cloud storage, the hard drive in your local computer or smartphone, and any portable devices. Data at rest is vulnerable to unauthorized access, so special care should be taken to maintain security protocols.
Learn more details from Wikipedia: Data at Rest and corresponding references.
Transfer - Data in Transit
Data in transit is digital data which is exchanged between the computing machines at the exact moment of the transfer. The source and destination locations may be on a local network or communicate over a public network (e.g., internet). There are various methods to secure data in motion, such as Secure File Transfer Protocol (SFTP), Secure HyperText Transfer Protocol (HTTP), Off the Record Messaging (OTR), Peer to Peer Communication (P2P), and Secure Sockets Layer (SSL) for data encryption. You use most of these security protocols in your daily life by browsing websites, logging into banking systems, etc. However, when communicating computing machines in scientific projects, especially when using HPC infrastructure, it is popular to use Secure Shell Protocol (SSH). It is a method for secure remote login from local computing machine to another computer or network. When connected, also the transmission of data is available. You can learn more about data transferring in section Remote Data Access.
Learn more details from Wikipedia: Data in Transit and corresponding references.
Explore also:
★ PentaSecurity Blog: What Are The Top Secure Data Transmission Methods?
Process - Data in Use
Data in use is digital data being actively processed by computer applications at the exact moment. That data is temporarily stored in random-access memory (RAM), processor registers, or hardware cache.
Learn more details from Wikipedia: Data in Use and corresponding references.